
 Last weekend I upgraded all my Servers to the last VMware ESXi release (7.0.1 C) and this article is meant to describe all steps I performed.
Last weekend I upgraded all my Servers to the last VMware ESXi release (7.0.1 C) and this article is meant to describe all steps I performed.
Just a recommendation before starting. I worked in my lab that it’s not a production environment.
MyLAB before upgrade:
- NUC8i7beh2
- VMware ESXi 7.0.0 (Build 16324942)
- Every NUC has three more network cards added to the embedded standard NIC. They have been obtained through the USB ports leveraging three adapter USB/Ethernet and the flings driver. Please refer to the FLINGS website to get all info.
The procedure is composed of two main phases and this article will cover the first part.
Phase 1: Creating a customize ISO
Is this step required?
Oh well, it depends if the Standard ESXi VMware ISO has already the driver of your embedded network card inside. The standard ISO, unfortunately, does not contain the NUC8i7BEH network drive (it is named ne1000)
If you upgrade the ESXi through the standard ISO, the process fails with the error shown in picture 1.
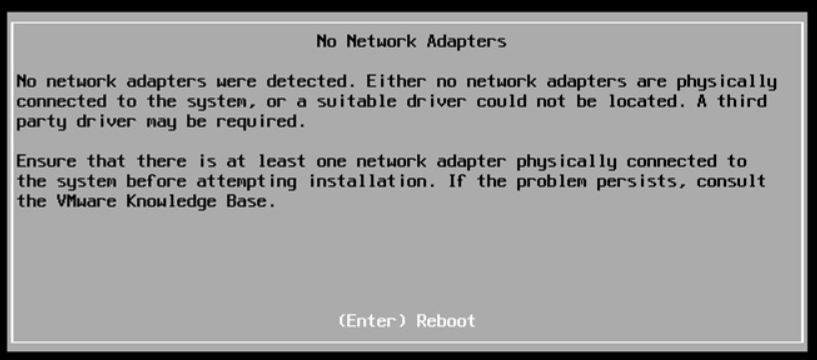 Picture 1
Picture 1
How to get over it?
Before upgrading it, it’s necessary to know the driver used by the embedded NIC Card. If you don’t know it, please read the next instructions carefully (they are command launched on host ESXi you are going to upgrade):
1. lspci -v | grep -A1 -i ethernet
take a note of the string composed of 4:4 values ( xxxx:yyyy)
2. lspci -n | grep xxx:yyy
take a note of how the nic is named (in my case [vmnic0])
The next step is getting the name of the driver directly from the VMware website (Matrix compatibility).
From that web page, filling up the empty field with the value yyyy and filtering the result by IO Devices, it’s possible to get the device driver name.
For my LAB the result is shown in picture 2 where I highlighted the device driver name in yellow.
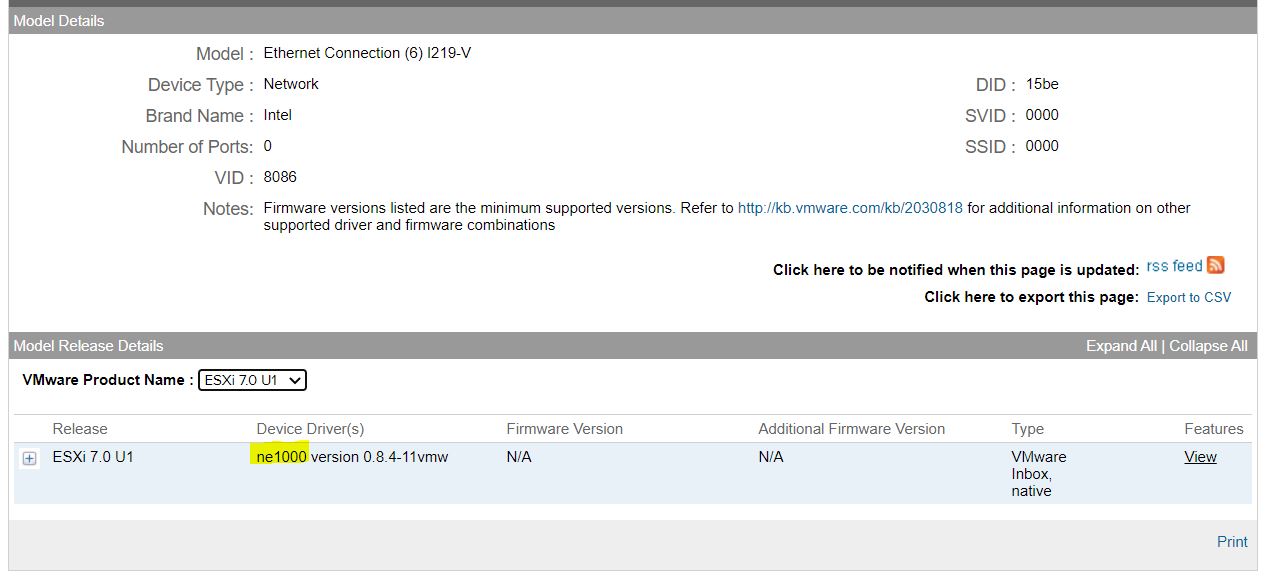 Picture 2
Picture 2
The last command to check if the driver is already installed (It should be present) is:
3. vmkload_mod -l | grep “Device Driver”
In my case: vmkload_mod -l | grep ne1000
ne1000 1 352
Optional: if you use the USB ports to add more NIC, please uninstall the fling drivers before proceeding.
4. esxcli software vib remove –vibname=vmkusb-nic-fling (before vibname two scores – – )
It’s time to create our custom ISO
a- Download the offline bundle from VMware Site, for example:
VMware- ESXi-7.0U1c-17325551-depot.zip
b- Download the NUC ethernet driver for your device (ne1000 in my case).
I found an useful PowerShell script to get it:
#add the software repository
Add-EsxSoftwareDepot https://hostupdate.vmware.com/software/VUM/PRODUCTION/main/vmw-depot-index.xml
#define as variable the name of the driver
$vib = Get-EsxSoftwarePackage ne1000
$vib | select Name,Version | ft -AutoSize
$vib[4] | fl
#Get the driver
Invoke-WebRequest $vib[4].SourceUrls[0] -OutFile d:\pkg\ne1000_0.8.4-10vmw.700.1.0.15843807.vib
c- The PowerShell script to create a custom ISO is available on VMware Front Experience Site.
This great script has a lot of options; please refer to the official documentation to see how to create the ISO.
In my case I just launched the following command:
.\ESXi-Customizer-PS-v2.6.0.ps1 -v701 -izip D:\ISO\ESXi-7-0-1\VMware-ESXi-7.0U1c-17325551-depot.zip -pkgDir D:\pkg\ -OutDir D:\ISO\ESXi-7-0-1\ -nsc
d- The last step is creating a bootable USB pen using the just created custom ISO as a source.
I have chosen Rufus to perform this task.
In the next article, we are going to see the final step to upgrade the NUC
 Picture 1
Picture 1 Picture 2
Picture 2 Picture 3
Picture 3 Picture 4
Picture 4 Picture 5
Picture 5 Picture 6
Picture 6 Picture 7
Picture 7 Picture 8
Picture 8 Picture 1
Picture 1
 Picture 3
Picture 3 Picture 4
Picture 4 Picture 5
Picture 5 Picture 6
Picture 6 Picture 7
Picture 7 Picture 8
Picture 8 Picture 9
Picture 9 Picture 10
Picture 10 Picture 11
Picture 11 Picture 12
Picture 12 Picture 13
Picture 13 Picture 14
Picture 14 Picture 15
Picture 15 Picture 16
Picture 16 Picture 17
Picture 17 Picture 18
Picture 18 Picture 19
Picture 19 Picture 1
Picture 1 Picture 2
Picture 2 Picture 3
Picture 3 Picture 4
Picture 4 Picture 5
Picture 5 Picture 6
Picture 6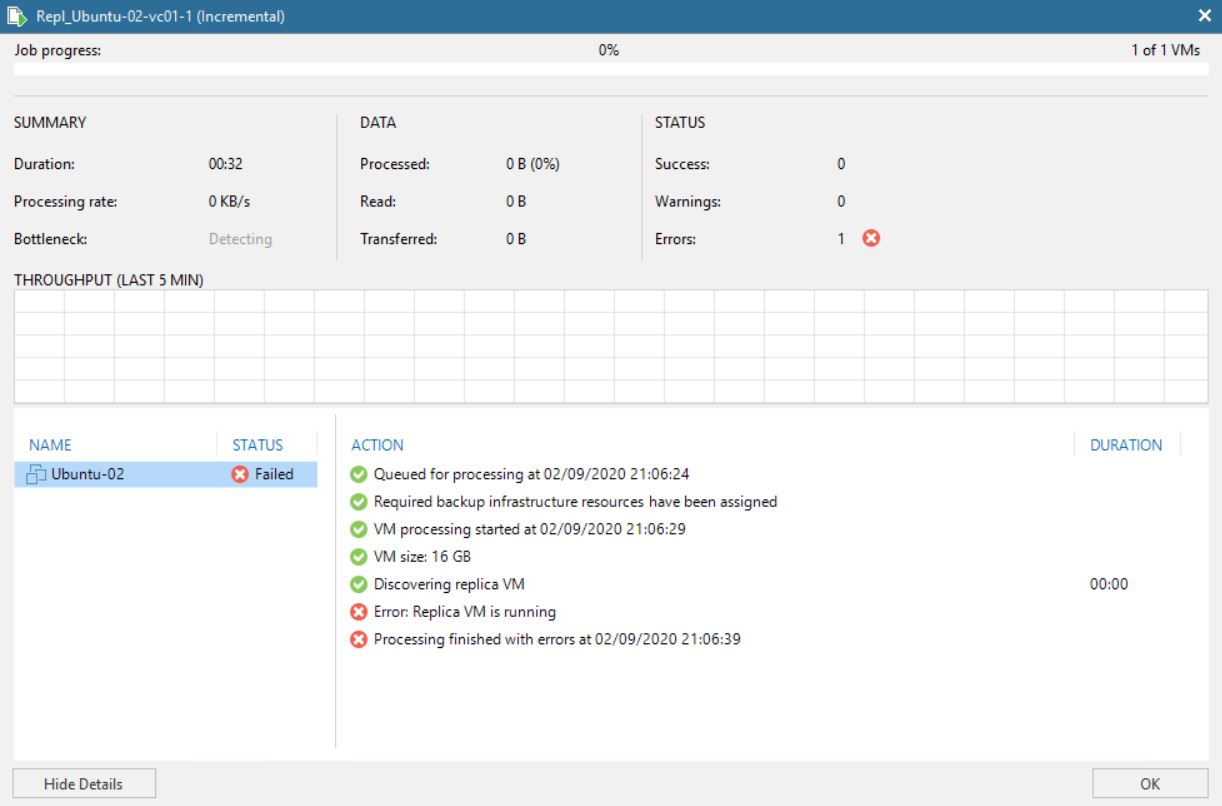 Picture 7
Picture 7 Picture 8
Picture 8 Picture 9
Picture 9 Picture 10
Picture 10 Picture 11
Picture 11 Picture 12
Picture 12 Picture 13
Picture 13 Picture 14
Picture 14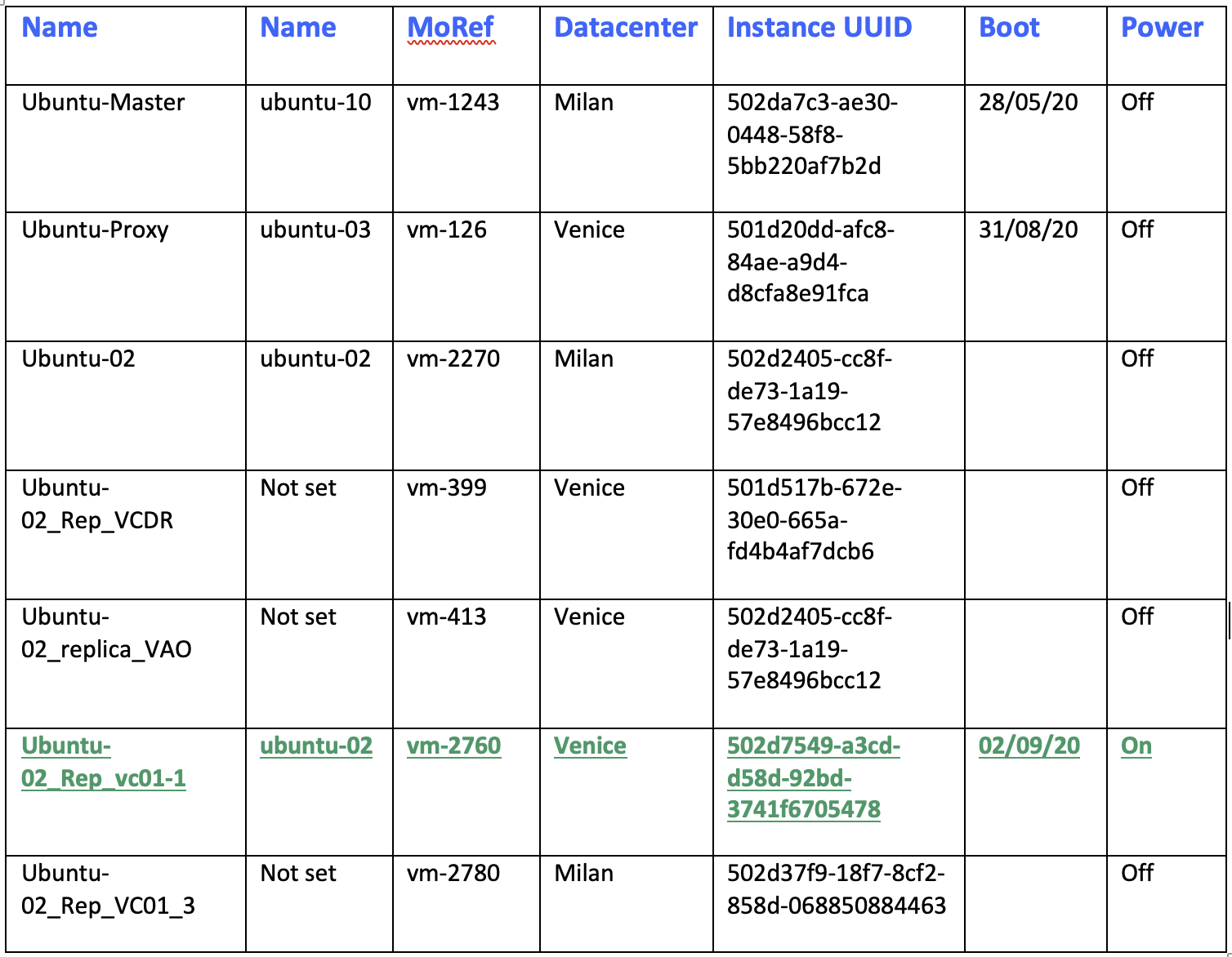 Table 1
Table 1 Table2
Table2