Una delle funzionalità avanzate e più importanti di kubernetes è l’health-check che permette di controllare l’integrità dei servizi.
E’ un ulteriore layer che aggiunge ai controlli standard che garantiscono che i processi dell’ applicazione siano sempre in esecuzione (livenessProbe), i controlli di integrità delle applicazioni (ReadinessProbe)
Il vantaggio dell’ health-check è che:
E’ specifico per ogni container.
Utilizza la stessa logica dell’applicazione (ad esempio, il caricamento di una pagina Web, il ping di un DB).
Il livenessProbe determina se l’applicazione sta funzionando correttamente. In caso contrario l’applicazione viene riavviata.
Il ReadinessProbe descrive quando il container è pronto a soddisfare le richieste degli utenti (e quindi del servizio)
La configurazione dell’health-check avviene attraverso l’aggiunta delle voci livenessProbe e ReadinessProbe al file yaml di configurazione del POD (vedi figura 1)
Figura 1
PORT-FORWARDING
Il port forwarding autorizza il servizio (configurato a livello POD) a comunicare sia con con altri POD, che con l’esterno. Senza Port-Forwarding, il servizio è totalmente isolato.
L’esempio più semplice è quello di un sito web. Fintanto che non è avviato il port-forwarding, le pagine del sito non sono disponibili agli utenti.
Nel nostro esempio (some-mysql), dopo che il POD è stato avviato, il comando per abilitare il port-forwarding dell’applicazione sulla porta 8000 è :
kubectl port forward some-mysql 8000:8000
Sul sito www.gable.it è disponibile un articolo che approfondisce la tematica networking di ambienti Container. Per leggerlo cliccate qui.
In uno dei prossimi articoli parleremo dei bilanciatori di carico che aiutano la gestione del networking.
Nei precedenti articoli, abbiamo visto che i container sono dei luoghi “astratti” dove girano le applicazioni sotto forma di immagini.
I POD sono l’aggregazione di più container.
Un servizio è l’aggragazione di più POD.
L’immagine di figura 1 mostra il concetto appena esposto.
Figura 1
Tutte le applicazioni (immagini) presenti all’interno dello stesso POD, avranno lo stesso indirizzo IP (condiviso) e lo stesso Hostname (UTS NameSpace).
La comunicazione tra i container all’interno dello stesso HOST avviene attraverso POSIX o le IPC di System V
Immaginate ora di voler erogare il servizio “the-gable-svc“, costruito con due immagini (container): un Database e un Front-End.
In fase di progetto è meglio disegnare un unico POD che contenga i due contanier (figura 2) oppure due POD con ognuno un container (figura 3)? (1POD x 2 CONTAINER oppure 2 POD x 1 CONTAINER)
Figura 2
Figura 3
Per rispondere accuratamente è necessario comprendere quale applicazione ha la necessita di maggiore scalabilità e flessibilità.
Nel nostro esempio è il DB che per gestire picchi di accesso, potrebbe richiedere maggiori risorse (RAM & CPU).
Se avessi disegnato un unicoPOD, l’aumento delle risorse coinvolgerebbe entrambe le applicazioni, andando di fatto a non ottimizzare il dispendio energetico.
Nota 1: Le risorse CPU & RAM sono assegnate durante la creazione del POD.
E’ sempre meglio crearepiù POD?
Quest’ultima affermazione non è allineata con la politica di resilienza di K8s, dove i POD dovrebbero girare su host fisici differenti (k8s è un cluster).
Per risolvere la dipartita, esista una buona regola:
Se il servizio funziona correttamente anche se i PODsono distribuiti su più host, allora è meglio utilizzare più POD (figura 2).
La Figura 4 mostra il contenuto del file mysql-pod.yaml che crea il POD per l’applicazione mySQL.
Figura 4
Vediamo la sintassi di base di gestione del POD:
Per avviarlo è sufficiente lanciare il comando: kubectl apply -f mysql-pod.yaml
Per verificarne lo stato: kubectl get pods
Per ottenere tutti i dettagli: kubectl describe pods some-mysql
Se volessimo cancellarlo: kubectl delete -f mysql-pod.yaml
Per oggi è tutto a tra poco dove parleremo di Accesso al POD, come copiare files e tanto altro ancora.
Nei precedenti articoli abbiamo visto alcuni dettagli di come è costruita l’architettura di Kubernetes.
Oggi verranno descritti i meccanismi di funzionamento del motore kubernetes indicando il nome di ogni componente; per rimanere fedeli al paragone del motore dell’autovettura, parleremo degli alberi acamme, valvole, bronzine, … che afferiscono al Cloud Native
Nota1: Non verrà trattata l’installazione di k8s in Datacenter, Cloud e Laboratorio, la rete ha già messo a disposizione esaustivi tutorial.
Per i familiarizzare con k8s vi consiglio di utilizzare Minikube (Piattaforma Linux) Docker Desktop (piattaforma Windows & Mac).
Iniziamo!
Kubernetes Master: E’ il nodo principale del cluster sul quale girano tre processi vitali per l’esistenza del cluster.
kube-apiserver
kube-controller-manager
kube-scheduler
Nel master node è inoltre presente il DataBaseetcd, che memorizza tutte le configurazioni create nel cluster.
I nodi che si fanno carico di far girare le applicazioni e quindi i servizi sono detti worker node. I processi presenti sui worker node sono:
Kubelet
kube-proxy
kubelet :Un agente che è eseguito su ogni nodo del cluster. Si assicura che i container siano eseguiti in un pod.
Kube-Proxy: Ha la responsabilità di gestire il networking, dalle regole di Routing a quelle di di Load Balancing.
Nota 2: K8s cercherà di utilizzare tutte le librerie disponibili a livello di sistema operativo.
kubectl: E’ Il client ufficiale di Kubernetes (CLI) attraverso il quale è possibile gestire il cluster (Kube-apiserver) utilizzando le API.
Alcuni semplici esempi di comandi kubectl sono:
kubectl version (indica la versione di k8s installata)
kubectl get nodes (scopre il numero di nodi del cluster)
kubectl describe nodes nodes-1 (mostra lo stato di salute del nodo, la piattafoma sulla quale k8s sta girando (Google, AWS, ….) e le risorse assegnate (CPU,RAM)).
Container Runtime: E’ la base sulla quale poggia la tecnologia k8s.
kubernetes supporta diverse runtime tra le quali ricordiamo, container-d,cri-o, rktlet.
Nota 3: La runtime Docker è stata deprecata a favore di quelle che utilizzano le interfacce CRI; le immagini Docker continueranno comunque a funzionare nel cluster.
Gli oggetti base di Kubernetes sono:
Pod
Servizi
Volumi
Namespace
I controllerforniscono funzionalità aggiuntive e sono:
ReplicaSet
Deployment
StatefulSet
DaemonSet
Job
Tra iDeployment è indispensabile menzionare Kube-DNSche fornisce i servizi di risoluzione dei nomi. Dalla versione kubernetes 1.2 la denominazione è cambiata in Core-dns.
Add-On: servono a configurare ulteriori funzionalità del cluster e sono collocati all’interno del name space kube-system (come Kube-Proxy, Kube-DNS, kube-Dashboard)
Gli Add-on sono categorizzati in base al loro utilizzo:
Add-on di Netwok policy. (Ad esempio l’add-on NSX-T si preoccupa della comunicazione tra l’ambiente K8s e VMware)
Add-on Infrastrutturali(Ad esempio KubeVirt che consente la connessione con le architetture virtuali)
Add-on di Visualizzazione e Controllo (Ad esempio Dashboard un’interfaccia web per K8s).
Per la messa in esercizio, gli Add-on utilizzano i controller DaemonSet e Deployment.
L’immagine di figura 1 riepiloga quanto appena esposto.
Una buona modalità per descrivere gli ambient cloud-native è rifarsi all’immagine della vostra autovettura.
Il container è il motore, k8s è la centrale elettronica che gestisce il buon funzionamento del mezzo, i conducenti, indicando il percorso e la meta, selezionano il tipo di servizio che dovrà essere erogato.
L’articolo di oggi vi svelerà alcuni dettagli di architettura per comprendere come “l’automobile” riesce a giungere la destinazione in modalità efficente.
I Container sono di due tipologie:
Il primo è detto System Container. E’ la carrozzeria dell’autovettura (intendo dalle lamiere a sedili, volante, leva del cambio e accessori).
Spesso per semplicità di creazione è una Virtual Machine (VM) con sistema operativo Linux (può essere anche Windows).
I servizi più comuni presenti nella VM sono ssh, cron e syslog, il File System è di tipo ext3, ext4, ecc.
La seconda tipologia è detta ApplicationContainer ed è il luogo dove l’immagine realizzerà le attività.
Nota1: L’immagine non è un singolo e grosso file. Di norma sono più file che attraverso un sistema interno di puntamento incrociato permettono all’applicazione di operare nel modo corretto.
L’application Container (d’ora in avanti solo container), ha una modalità di funzionamento basata su una rigida logica, dove tutti livelli (layers) hanno la peculiartità di comunicare tra loro e sono interdipendenti.
Figura 1
Questo approccio è molto utile poiché è in grado di gestire i cambiamenti che possono avvenire nel corso del tempo in modalità efficace perchè gerarchica.
Facciamo un esempio: Nel momento in cui avviene un cambio di configurazione del servizio, per il quale viene aggiornato il Layer C, il Layer A e B non ne sono impattati, il che significa che NON devono essere a loro volta modificati.
Visto i Developer hanno piacere nell’affinare le proprie immagini (program file) piuttosto che le dipendenze, ha senso impostare la logica di servizion nella modalità indicata in figura 2 dove le dipendenze non sono impattate da una nuova immagine.
Figura 2
Nota2 : Il File system sul quale si appoggiano le immagini (nell’esempio del motore dell’auto parliamo di pistoni, bielle, alberi …) è principalmente di tre differenti tipologie:
Overlay
Overlay 2
AUFS
Nota3: Un buon consiglio lato sicurezza è quello do non costruire l’architettura in modo che le password siano contenute nelle immagini (Baked in – Cucinata)
Una delle splendide novità introdotte nel mondo containers è la gestione delle immagini:
In un ambiente classico di alta affidabilità, l’applicazione viene installata su ogni singolo nodo del cluster.
Nei container, l’applicazione viene scaricata e distribuita solo quando il carico di lavoro richiede maggiori risorse, quindi un nuovo nodo del cluster con una nuova immagine.
Per questo motivo le immagini sono salvate all’interno di magazzini “virtuali”, che possono essere locali oppure distribuiti su internet. Sono chiamati “Register Server”.
I più famosi sono Docker Hub, Google Container Registry, Amazon Elastic Container Registry, Azure Container Registry.
Concludiamo il presente articolo parlando di gestione delle risorse associate ad un servizio.
La piattaforma container utilizza due funzionalità denominate Cgroup e NameSpace per assegnare le risorse che lavorano a livello di kernel.
Lo scopo del Cgroup è di assegnare allo specifico processo (PID) le corrette risorse (CPU&RAM).
I Name space hanno lo scopo di ragguppare i differenti processi e fare in modo che siano isolati tra loro (Multitenancy).
La tipologia di NameSpace puo interesare tutti i componenti del servizio come indicato nella lista qui sotto.
Cgroup
PID
Users
Mount
Network
IPC (Interprocess communication)
UTS (consente a un singolo sistema di apparire con nomi di host e domini diversi e con processi diversi, utile nel caso di migrazione)
Un esempio di limitare le risorse di un’applicazione è indicata nella figura 3 dove l’immagine thegable, scaricata dal Register Server grcgp,ha un limite di risorse RAM e CPU assegnate.
Questo nuovo articolo vuole indicare le nuove opportunità di lavoro create da un ambiente cloud-native.
L’immagine n°1 mostra i quattro livelli principali necessari all’architettura per funzionare correttamente (parte rettangolare sinistra).
Sul lato destro (cerchi) sono rappresentati le occupazioni dell’operatore rispetto ad ogni singolo livello.
Immagine 1
Dal basso verso l’alto:
1- Gli Storage and Network Operator (SNO) hanno la responsabilità di gestire l’architettura hardware.
Il numero dell’attività del ruolo può diminuire in caso di implementazione in un cloud pubblico o IaaS (Infrastructure as a Service)
2- L’Operatore del sistema operativo (OSO) lavora al livello del sistema operativo in cui viene eseguito il servizio k8s.
L’OSO ha bisogno di competenza in Linux e Windows. Sono spesso richieste competenze nell’architettura di virtualizzazione come VMware, RedHat, Nutanix, ecc.
Se l’architettura è stata affittata dal cloud pubblico o in generale in un IaaS, le competenze devono coprire questa nuova architettura.
3- L’operatore di orchestrazione (OO) lavora con il nucleo dell’ambiente di amministrazione cloud-native. Questo mondo ha bisogno di molte nuove abilità.
L’automazione è il figlio dell’orchestrazione.
Il concetto principale è che l’OO dovrebbe avere competenze sufficienti per riuscire a seguire tutti i processi di “Integrazione Continua” e “Consegna Continua” (spesso chiamata CI/CD).
L’immagine 2 dà un’idea a riguardo
Le frecce centrali mostrano il flusso per consentire l’erogazione di un servizio.
Per ogni singola freccia ci sono nuovi strumenti da conoscere per gestire l’intero rilascio del servizio.
Solo alcuni esempi: per testare l’ambiente è possibile lavorare con cetriolo o Cypress.io, per la distribuzione e la costruzione è possibile utilizzare Jenkins… e così via…
Immagine 2
Nota 1: ci sono così tante piattaforme disponibili che la scelta di quella giusta potrebbe essere molto impegnativa
4- L’operatore di sviluppo è il ruolo delle persone che sono scritte righe di codice. Spesso usano software per gestire attività come Jira Core e Trello.
Nota 2: A mio parere personale, il fornitore che crea un livello software in grado di gestire centralmente tutte queste 6 attività principali avrà un vantaggio competitivo rispetto ai concorrenti.
I grandi fornitori stanno già giocando: RedHat sta lavorando dall’inizio con la sua piattaforma (OpenStack), VMware ha rilasciato Tanzu, Nutanix con Carbonite e Microsoft giocherà il suo ruolo con la nuova versione di Windows 2022.
L’unico buon suggerimento che posso darti è quello di studiare questo nuovo e fantastico mondo.
Kubernetes (k8s), è una piattaforma open source, introdotta da Google, introdotta come un semplice strumento di orchestrazione di container ma è diventata di fatto la piattaforma cloud-native.
Perché “k8s” viene così ampiamente utilizzato?
Poichè è in grado di rispondere efficacemente alle richieste di qualità di servizio degli utenti, di adattarsi alla creatività dei cloud-architect e di essere così stabile da soddisfare le richieste delle operation.
Tali vantaggi possono essere così riassunti:
Affidabile
Scalabile
Auto-guarigione
Veloce
Efficiente
Sicuro
Agile
Trasportabile
Nel presente articolo svilupperemo le 8 argomentazioni appena indicate:
1-Affidabilità significa un’architettura in grado di funzionare anche se una parte di essa non è più disponibile. K8s è stato pensato con una filosofica nativamente clusterizzata.
2- La scalabilità è necessaria per gestire qualsiasi picco di carico di lavoro. In altre parole, è in grado di risponde a richieste di nuove risorse on-demand.
Il modello di architettura sul quale si basa è il disaccoppiamento. Ogni singolo componente ha le proprie caratteristiche e può essere facilmente aggiunto all’ambiente k8s.
Attraverso i file di configurazione i vari oggetti sono autorizzati a comunicare tra loro.
I componenti principali dell’architettura k8s sono i nodi, i componenti dei servizi k8s sono i bilanciatori del carico, i name-spaces e così via (vedi prossimi articoli)
3-Guarigione: K8s agisce per assicurare che lo stato corrente corrisponda automaticamente allo stato desiderato dell’architettura.
4-Veloce: K8s è in grado di distribuire i componenti immediatamente. In questo modo è possibile rispondere ad una richiesta di gestione del sovraccarico e/o necessità di implementare velocemente nuovi servizi.
5- L’efficienza è il rapporto tra il lavoro utile e la quantità totale di energia utilizzata per ottenere il risultato. K8s per la sua architettura ha il miglior rapporto perché ha l’essenzialità nel suo DNA.
6- La sicurezza lavora a stretto contatto con k8s.
a- Le immagini che girano nei contenitori sono per la loro definizione immutabili. Questo approccio ha un grande vantaggio perché:
–Nessuna modifica viene implementata a livello di sistema (contenitore).
-Niente può modificare il nucleo del servizio a meno che l’intera immagine non venga eliminata e ridistribuita.
Confrontiamo questo approccio con un ambiente standard, dove è presente una VMLinux.
Se su quest’ultima volessimo installare, modificare, aggiornare un’applicazione, dovremmo agire via apt-get sui pacchetti necessari.
Così facendo modificheremo l’ambiente aprendo di fatto una breccia in ambito sicurezza.
In K8s non viene modificata l’immagine ma cancellata e ricreata.
b- Un altro grande vantaggio è che le modifiche alla configurazione sono gestite tramite file dichiarativi (file di configurazione). Questi file hanno una descrizione dello stato finale del sistema. Il risultato è che mostrano l’effetto della configurazione prima che venga eseguita.
7-Agilità significa maggiore facilità ed efficienza nella creazione di immagini container rispetto all’utilizzo di immagini VM. Lo sviluppatore può scrivere codice indipendentemente dai problemi di compatibilità.
8- La portabilità crea lo standard del ciclo di vita dello sviluppo software.
Nota 1: la prima versione di Kubernetes risale al 2014 ed è stata creata per rispondere alla necessità di implementare una solida soluzione di cluster per ambienti container.

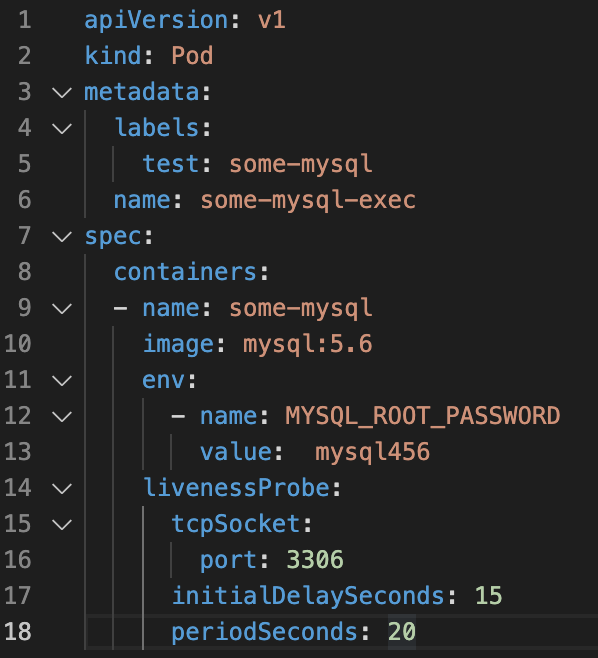 Figura 1
Figura 1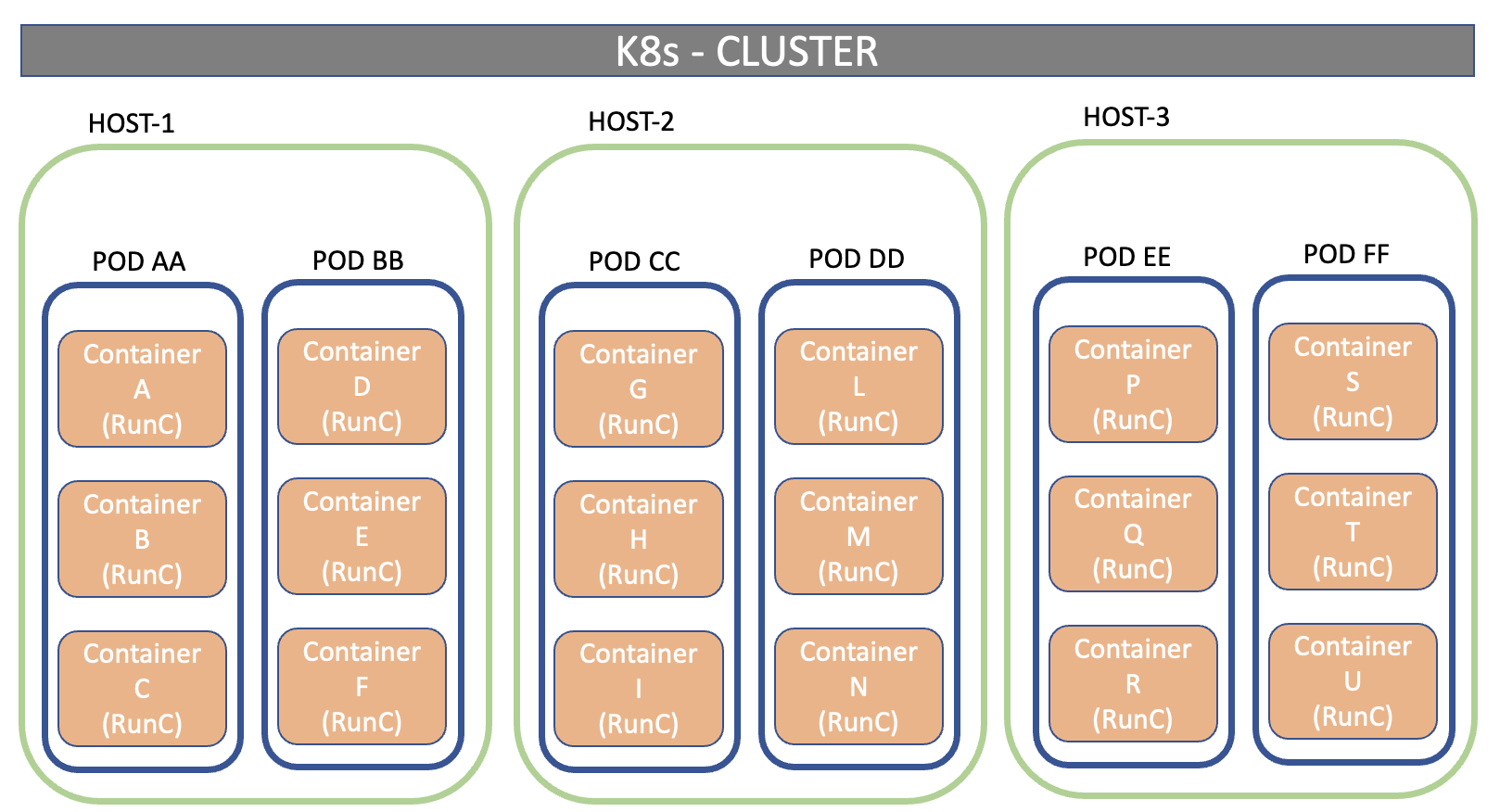 Figura 1
Figura 1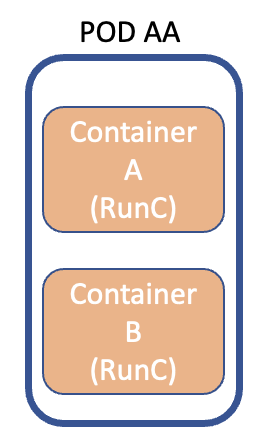 Figura 2
Figura 2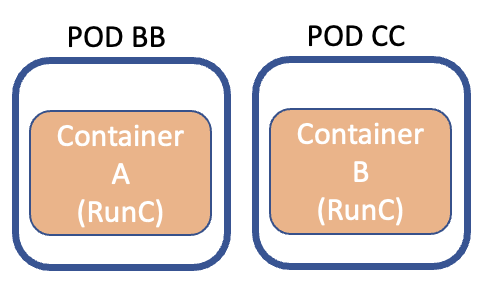 Figura 3
Figura 3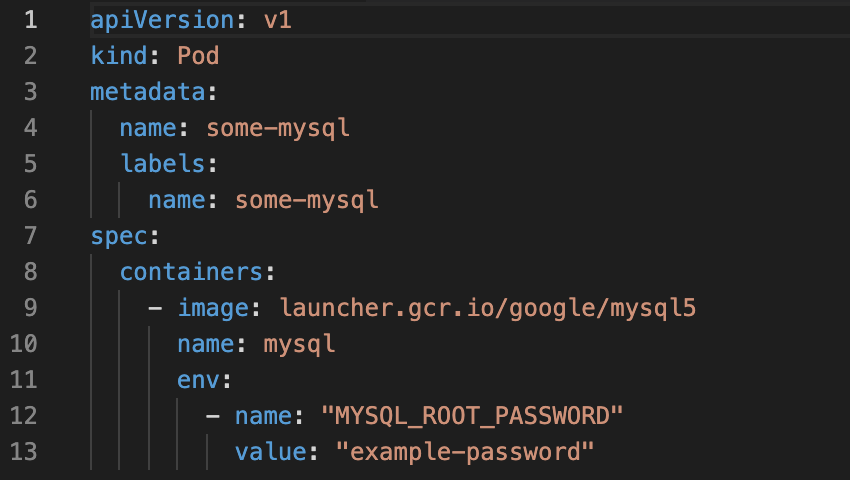 Figura 4
Figura 4
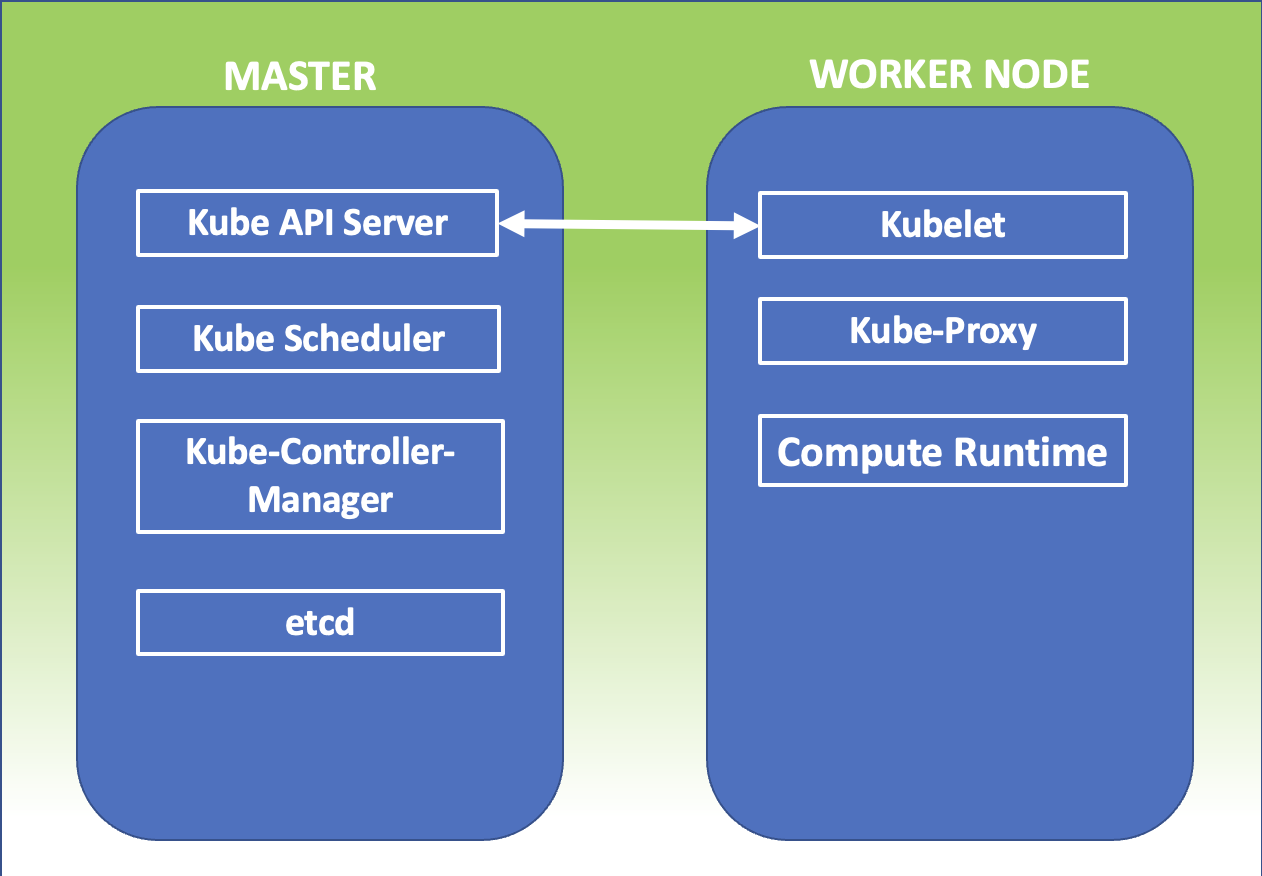 Figura 1
Figura 1
 Figura 1
Figura 1 Figura 2
Figura 2 Figura 3
Figura 3
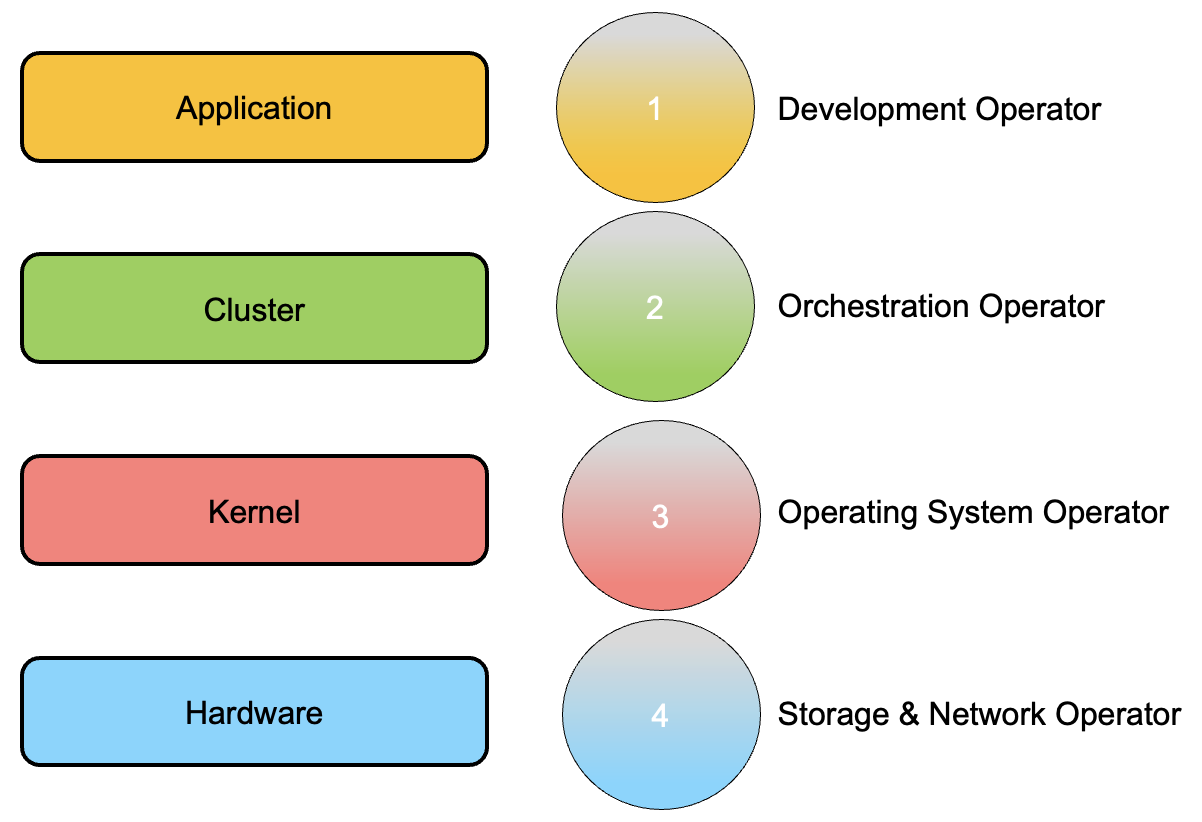 Immagine 1
Immagine 1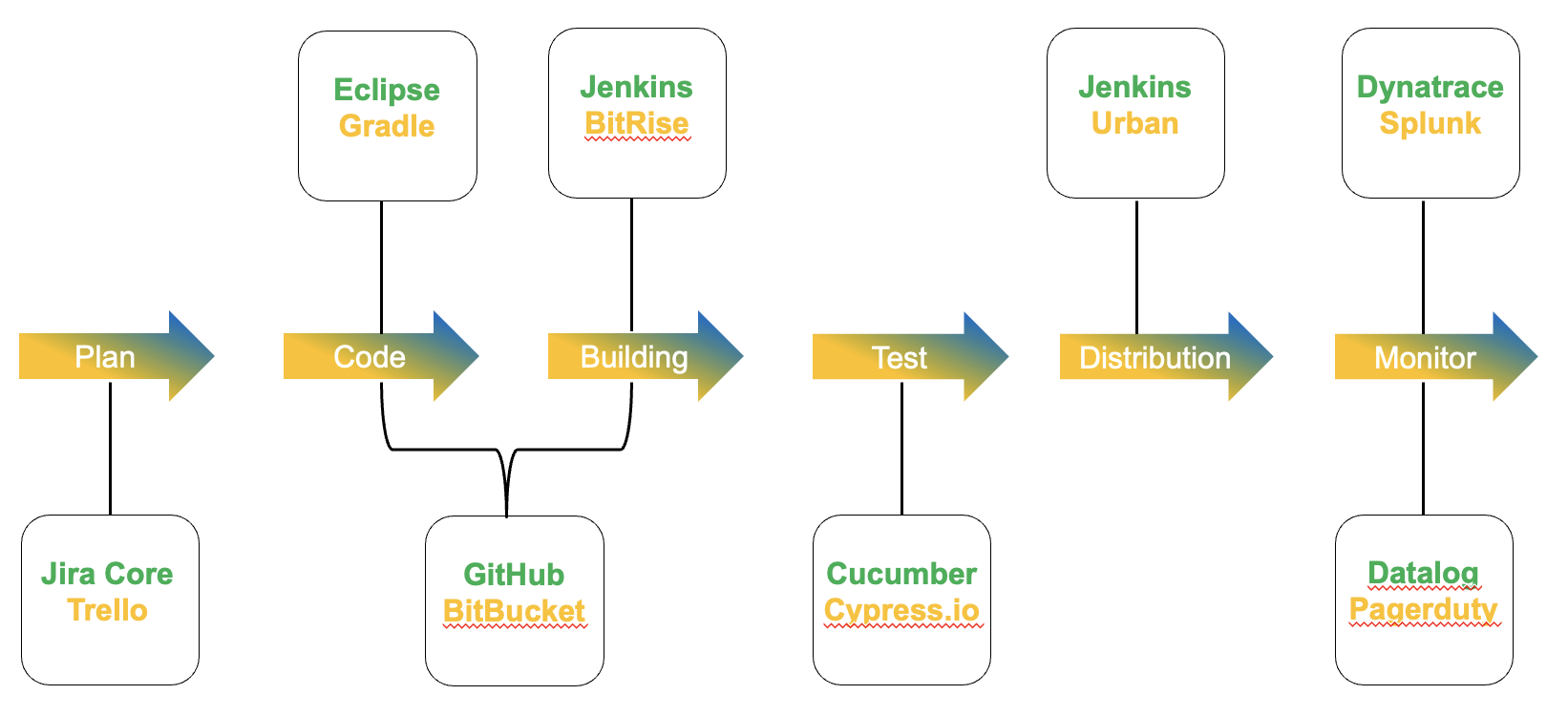 Immagine 2
Immagine 2