Il primo articolo del 2022 è dedicato a come proteggere le istanze Google (GCP).
Il flusso e l’architettura di protezione è riportato nell’immagine 1 dove sono presenti due componenti Veeam.
L’ istanza Veeam Backup for Google Platform (VBGP) ha il compito di realizzare backup e ripristini delle istanze GCP.
Veeam Backup & Replication (VBR) ha l’onere di gestire centralmente la movimentazione dei dati di Backup da e per il cloud (Data Mobility).
Immagine 1
Nota 1: VBGP può essere installato in modalità stand alone oppure utilizzando il wizard di VBR.
Nota 2: Il presente articolo mostrerà come agganciare da VBR un istanza VBGP già presente in GCP.
Vediamo in modalità dettagliata i passaggi:
Dalla console di VBR scegliamo la voce Backup Infrastructure.
Cliccando con il tasto destro del mouse, selezioniamo la voce add server e successivamente Google Cloud Platform (vedi immagine 2)
Immagine 2
Il prossimo passaggio è quello di inserire le credenziali di accesso al Service Account di Google (immagine 3)
Immagine 3
Il wizard prosegue chiedendovi di inserire il nome del server VBGP già creato (immagine 4)
Immagine 4
Dopo aver selezionato la tipologia di rete presente (immagine 5) il passaggio successivo è quello di inserire le credenziali di accesso al Repository (immagine 6).
Ricordo che la best practice di protezione è quella di effettuare il backup dell’istanza come snapshot, successivamente riversare la snapshot verso il Cloud Object Storage di Google.
Si rispetta così la regola del 3-2-1, avere cioè 3 copie dei dati (Produzione + Snapshot + Object Storage) su due differenti media (Storage primario + Object Storage) con una copia offsite (Object storage dovrebbe afferire ad un’altra region).
Immagine 5
Immagine 6
Concluso il wizard, sempre dalla console di VBR possiamo collegarci alla console al server VBGP (immagine 7) per iniziare a creare policy di protezione.
Immagine 7
Dopo aver inserito le credenziali di accesso (immagine 8)
Immagine 8
è possibile monitorare l’ambiente attraverso un overview delle istanze presenti, di quelle protette (immagine 9 & 10)
Immagine 9
Immagine 10
Gestire le politiche di protezione attraverso:
La creazione delle policy di Backup, indicando nome (immagine 12), selezionando il progetto (immagine 13), la region (immagine 14), le risorse (immagine 15), il target di Backup (immagine 16), la schedulazione e la tipologia di backup (immagini da 17 a 19)
Immagine 11
Immagine 12
Immagine 13
Immagine 14
Immagine 15
Immagine 16
Immagine 17
Immagine 18
Immagine 19
Le ultime due voci indicano la stima dei costi mensili per realizzare la policy di backup (immagine 20) e l’impostazione dei retry e delle notifiche (immagine 21)
Immagine 20
Immagine 21
Terminata la configurazione e dal monitoraggio verificato che la policy si è completata con successo, è possible procedere al ripristino (immagine 22).
Immagine 22
Le opzioni disponibili sono:
Intera Istanza
File e Cartelle
Le prossime immagini (23-24-25) mostrano i passaggi chiave per ripristinare l’ìntera istanza.
Immagine 23
Immagine 24
Immagine 25
Nel prossimo articolo vedremo come poter proteggere e rispristinare un DB Sql presente in un’istanza GCP
A partire dal 1 luglio 2022, la vendita di licenze perpetue per socket di Veeam Backup & Replication™, Veeam Availability Suite™, Veeam Backup Essentials™ e Veeam ONE™ cesserà sia ai clienti nuovi che a quelli esistenti.
I prodotti attualmente in esercizio, continueranno a funzionare ma non sarà possibile acquistare nuove licenze a Socket per effettuare un upgrade.
Le licenze acquistabili e disponibili sono le Veeam Universal License (VUL) che utilizzano come unità di misura il singoloworkload.
I vantaggi più importanti del modello VUL possono essere riassunti in:
Possibilità di proteggere qualsiasi workload supportato (ad esempio le istanze in AWS, Azure e GCP) e non solo le Virtual Machine VMware e Hyper-V.
Libertà di muovere le licenze a seconda della necessità tra tutti i workload supportati.
Nota 1: Ogni istanza può essere utilizzata per proteggere 500 GB dati sorgente di un NAS
Nota 2: Facciamo un esempio per semplificare il conteggio: ipotizziamo di dover proteggere un ambiente composto da 50 VM Hyper-V, 30 istanze in Azure (oppure in Aws oppure in GCP), 10 server fisici e 5 TB di dati.
Il numero totale di istanze è la somma algebrica di:
Dopo aver aggiornato i vCenter all’ultima versione disponibile, (7.0.3.00100), mi sono accorto che i backup precedentemente configurati non venivano completati con successo.
L’errore che compariva era il seguente: “Path not exported by the remote filesystem” (vedi immagine 1).
Immagine 1
Una veloce indagine sul sito VMware ha spiegato la ragione:
Quando la destinazione del backup è una share di tipo SMB, la VCSA non è in grado di scrivere sul target i file di backup. (https://kb.vmware.com/s/article/86069)
Riconfigurato il job in modo tale che scrivesse verso un target di tipo NFS, speravo di aver risolto questo inconveniente ma … un nuovo errore ha fatto la sua comparsa.
“Db health is UNHEALTHY, Backup Failed. Disable health check to take backup in the current state” (vedi immagine 2):
Immagine 2
Nuova indagine e nuova risposta esauriente da VMware.
Dalla kb 86084 (https://kb.vmware.com/s/article/86084) l’errore può comparire dopo aver installato la patch 7.0.3
La procedura è molto semplice e consiste nel collegarsi come utente root e via SSH alla VCSA e lanciare il seguente comando:
/usr/bin/dbcc -fbss embedded (vedi immagine 3).
Immagine 3
Completata l’operazione è possibile salvare la configurazione della VCSA (vedi immagini 4 e 5).
Veeam Backup & Replication (VBR) version 11 has a new feature and Mac users will fall in love with it.
It is now available for the backup and restores of your MACOS files.
It supports the last Operating Systems starting from High-Sierra (Big Sur 11.X.X / Catalina 10.15.X / Mojave 10.14.X / High Sierra 10.13.6).
Note 1: The Veeam Agent for Mac (VAM) version 1 supports the M1 processor via Rosetta.
Note 2: The VAM supports consistent data backup with snapshots for the APFS file system.
In the other file systems, the backup is created via a snapshot-less approach.
Note 3: At the moment it’s possible to perform the backup of user data (with a custom scope too). The image of the entire machine and a Bare Metal Restore are not available yet.
The configuration steps are quite easy as shown in the official guide:
To recap, the procedure consists of:
From the VBR console create a resource group using a flexible scope
Copy the files generated from VBR to the MAC to protect
Install the package to your machine and import the created configuration. (It allows the communication between VBR and the Mac)
From the VBR console creating the backup policy and apply it
The following video shows how it works in a managed VBR architecture.
Se negli ultimi 5 anni, la parola Cloud è stata quella più utilizzata (anche in modo inappropriato), negli ultimi cinque mesi la parola che sta rieccheggiando di più nel mondo IT è Digital Transformation.
Da Wikipedia:
“Digital Transformation (DT o DX) è l’adozione della tecnologia digitale per trasformare servizi e aziende, sostituendo processi non digitali o manuali con processi digitali o sostituendo la tecnologia digitale precedente con la tecnologia digitale più recente”.
Ancora: la Digital Transformation deve aiutare le aziende ad essere più competitive attraverso la rapida implementazione di nuovi servizi sempre in linea con le esigenze aziendali.
Nota 1: La trasformazione digitale è il paniere, le tecnologie da utilizzare sono le mele, i servizi sono i mezzi di trasporto, i negozi sono i clienti/clienti.
1. Tutte le architetture IT esistenti possono funzionare per la Trasformazione Digitale?
Preferisco rispondere ricostruendo la domanda con parole più appropriate:
2. La trasformazione digitale richiede che dati, applicazioni e servizi si spostino da e verso architetture diverse?
Sì, questo è un must ed è stato nominato Data Mobility.
3. La Data-Mobility significa che i servizi possono essere indipendenti dall’infrastruttura sottostante?
La miglior risposta credo che sia: nonostante al giorno d’oggi non esista un linguaggio standard che permetta a diverse architetture/infrastruttura di dialogare tra loro (on-premises & on cloud), le tecnologie di Data-mobility sono in grado di superare tale limitazione.
4. La Data Mobility è indipendente dai fornitori?
Quando uno standard viene rilasciato, tutti i fornitori vogliono implementarlo al più presto perché sono sicuri che queste funzionalità miglioreranno le loro entrate. Attualmente, questo standard non esiste ancora.
Nota 3: penso che il motivo sia che ci sono così tanti oggetti da contare, analizzare e sviluppare che lo sforzo economico per farlo non è al momento giustificato
5. Esiste già una tecnologia Ready “Data-Mobility”?
La risposta potrebbe essere piuttosto lunga ma, per farla breve, ho scritto il seguente articolo che si compone di due parti principali:
Livello applicazione (contenitore – Kubernetes)
Livello dati (backup, replica)
Application Layer – Container – Kubernetes
Nel mondo IT, i servizi sono eseguiti in ambienti virtuali (VMware, Hyper-V, KVM, ecc.).
Vi sono ancora alcuni servizi che girano su architetture legacy (Mainframe, AS400 ….), (vecchi non significa che non siano aggiornati ma solo che hanno una storia molto lunga)
Nei prossimi anni i servizi verranno implementati in un’apposita “area” denominata “container”.
Il contenitore viene eseguito nel sistema operativo e può essere ospitato in un’architettura Virtuale/Fisica/Cloud.
Perché i contenitori e le competenze su di essi sono così richiesti?
a. L’esigenza degli IT Manager è quella di spostare i dati tra le architetture al fine di migliorare la resilienza e ridurre i costi. b. La tecnologia Container semplifica la scrittura del codice dello sviluppatore perché ha un linguaggio standard e ampiamente utilizzato. c. I servizi eseguiti sul container sono veloci da sviluppare, aggiornare e modificare. d. Il contenitore è “de facto” un nuovo standard che ha un grande vantaggio. Superare l’ostacolo della mancanza di standard di comunicazione tra le architetture (private, ibride e cloud pubblico).
Un approfondimento sul punto d.
Ogni azienda ha il proprio core business e tutte hanno bisogno della tecnologia informatica.
Qualsiasi dimensione dell’azienda?
Sì, basti pensare all’ uso del cellulare, per prenotare un tavolo al ristorante o acquistare un biglietto per un film. Sono anche abbastanza sicuro che ci aiuterà a superare la minaccia Covid.
Questo è il motivo per cui continuo a pensare che l’IT non sia un “costo” ma un modo per ottenere più successo e denaro migliorando l’efficienza di qualsiasi azienda.
Anche Kubernetes ha delle funzionalità specifiche per consentire la mobilità dei dati?
Si, un esempio è Kasten K10 perchè ha tante e avanzate funzionalità di migrazione dei workload (l’argomento sarà ben trattato nei prossimi articoli).
Data-Layer
E i servizi che non possono essere ancora containerizzati?
C’è un modo semplice per spostare i dati tra diverse architetture?
Sì, è possibile utilizzando copie dei dati di VM e Server Fisici.
In questo scenario aziendale, è importante che il software possa creare backup/repliche ovunque si trovino i carichi di lavoro.
È abbastanza? No, il software deve essere in grado di ripristinare i dati all’interno delle architetture.
Ad esempio, un cliente può dover ripristinare alcuni carichi di lavoro on-premise della sua architettura VMware in un cloud pubblico o ripristinare un backup di una VM situata in un cloud pubblico in un ambiente Hyper-V on-premise.
In altre parole, lavorare con Backup/Replica e ripristino in un ambiente multi-cloud.
Le immagini successive mostrano il processo dei dati.
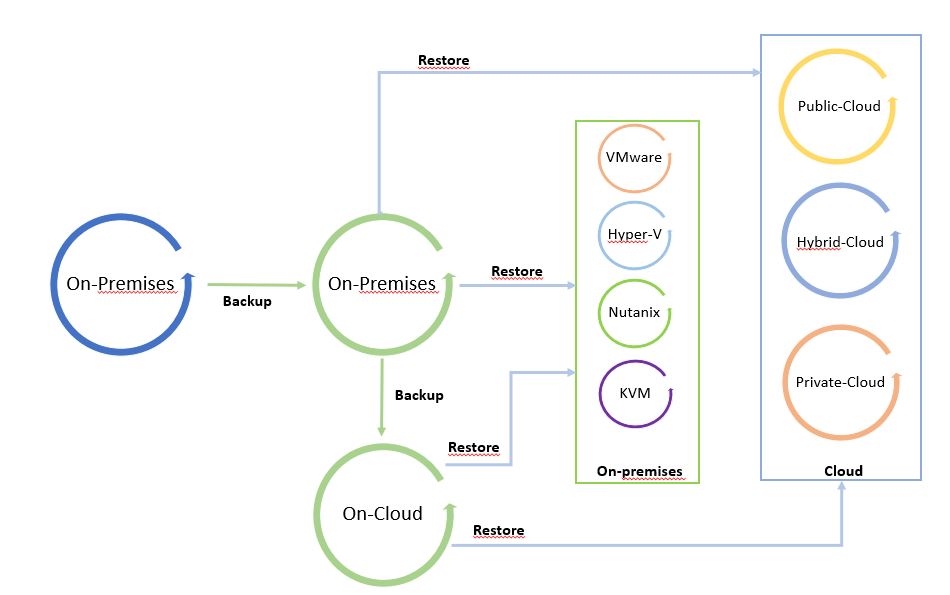
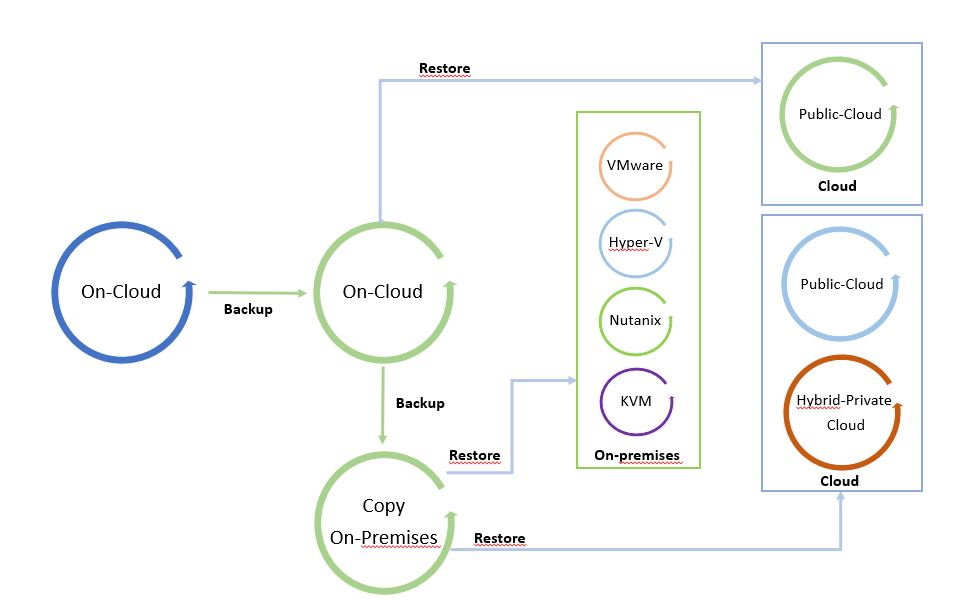
L’ho chiamato “Il ciclo dei dati” perché facendo leva su una copia di backup è possibile spostare liberamente i dati da e verso qualsiasi Infrastruttura (Cloud pubblico, ibrido, privato).
Le immagini 1 e 2 sono solo esempi del concetto di mobilità. Possono essere modificati aggiungendo tutte le piattaforme supportate dal software di cloud mobility.
Il punto di partenza dell’immagine 1 è un backup in locale che può essere ripristinato in locale e nel cloud. L’immagine 2 mostra il backup di un carico di lavoro sito in un cloud pubblico ripristinato su cloud o in locale.
È una via circolare in cui i dati possono essere spostati tra le piattaforme.
Nota 4: Un buon suggerimento è quello di utilizzare l’architettura di mobilità dei dati per configurare un sito di ripristino di emergenza a freddo (freddo perché i dati utilizzati per ripristinare il sito sono backup).
Immagine 1
Immagine 2
C’è un ultimo punto per completare questo articolo ed è la funzione Replica.
Nota 5: Per Replica intendo la possibilità di creare un mirror del carico di lavoro di produzione. Rispetto al backup, in questo scenario il carico di lavoro può essere avviato senza alcuna operazione di ripristino perché è già scritto nella “lingua” dell’host-hypervisor.
Lo scopo principale della tecnologia di replica è creare un sito di ripristino di emergenza a caldo (DR).
Maggiori dettagli su come orchestrare il DR sono disponibili su questo sito alla voce Veeam Disaster Recovery Orchestrator (conosciuto anche con il nome di Veeam Availability Orchestrator)
La replica può essere sviluppata con tre diverse tecnologie:
Replica Lun/Archiviazione
Split I/O
Snapshot
Tratterò questi scenari e i casi aziendali di Kasten K10 in articoli futuri.

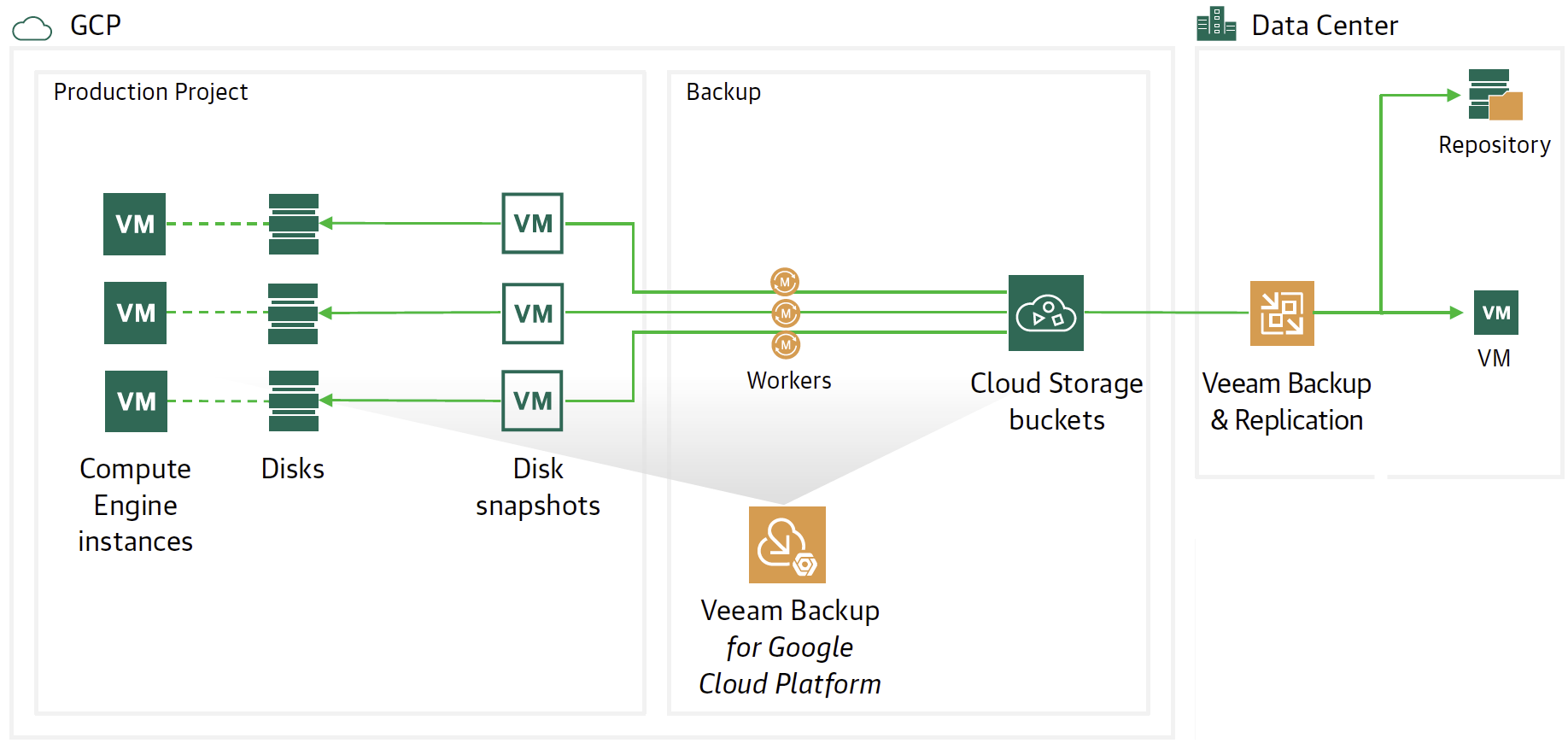 Immagine 1
Immagine 1 Immagine 2
Immagine 2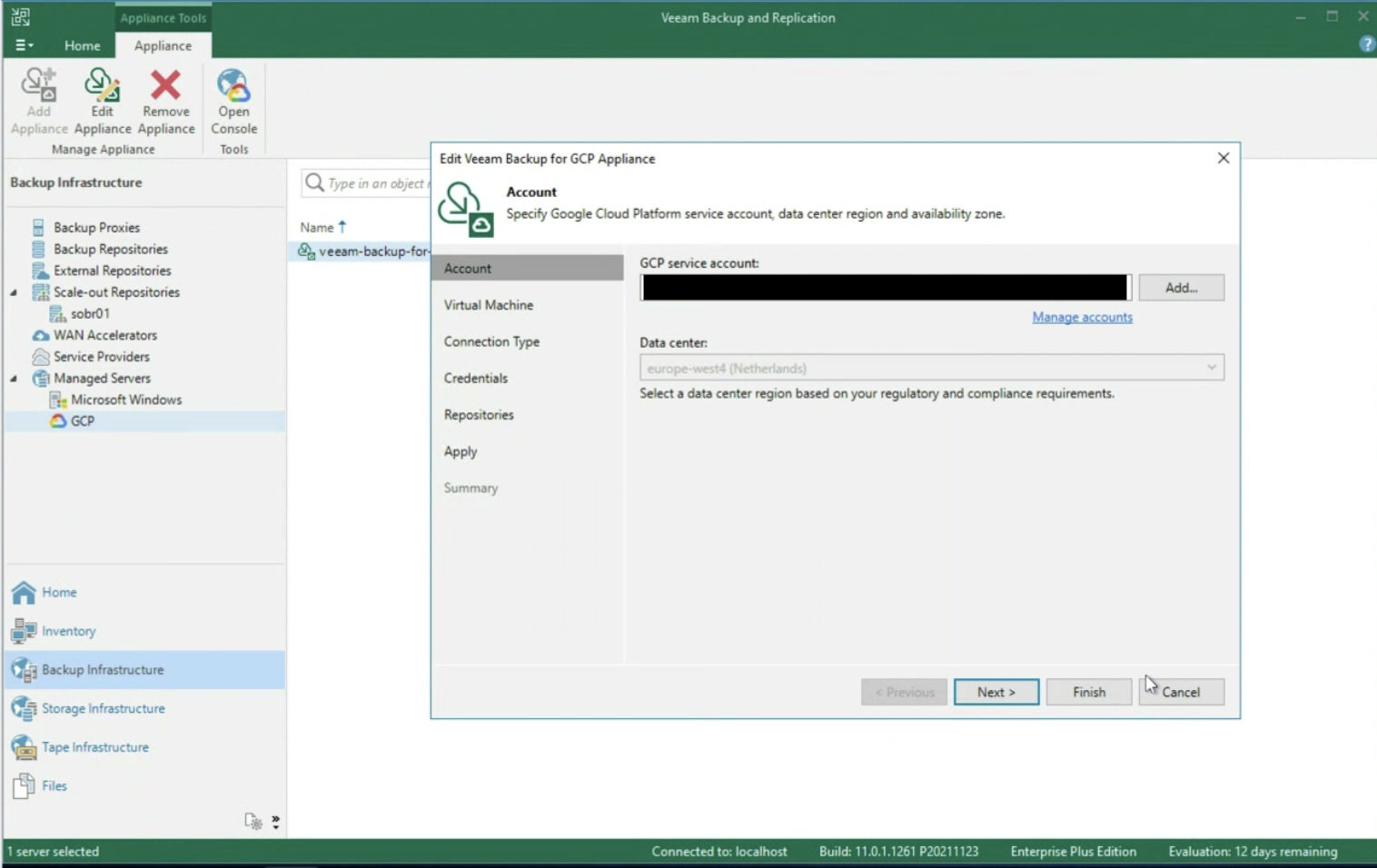 Immagine 3
Immagine 3 Immagine 4
Immagine 4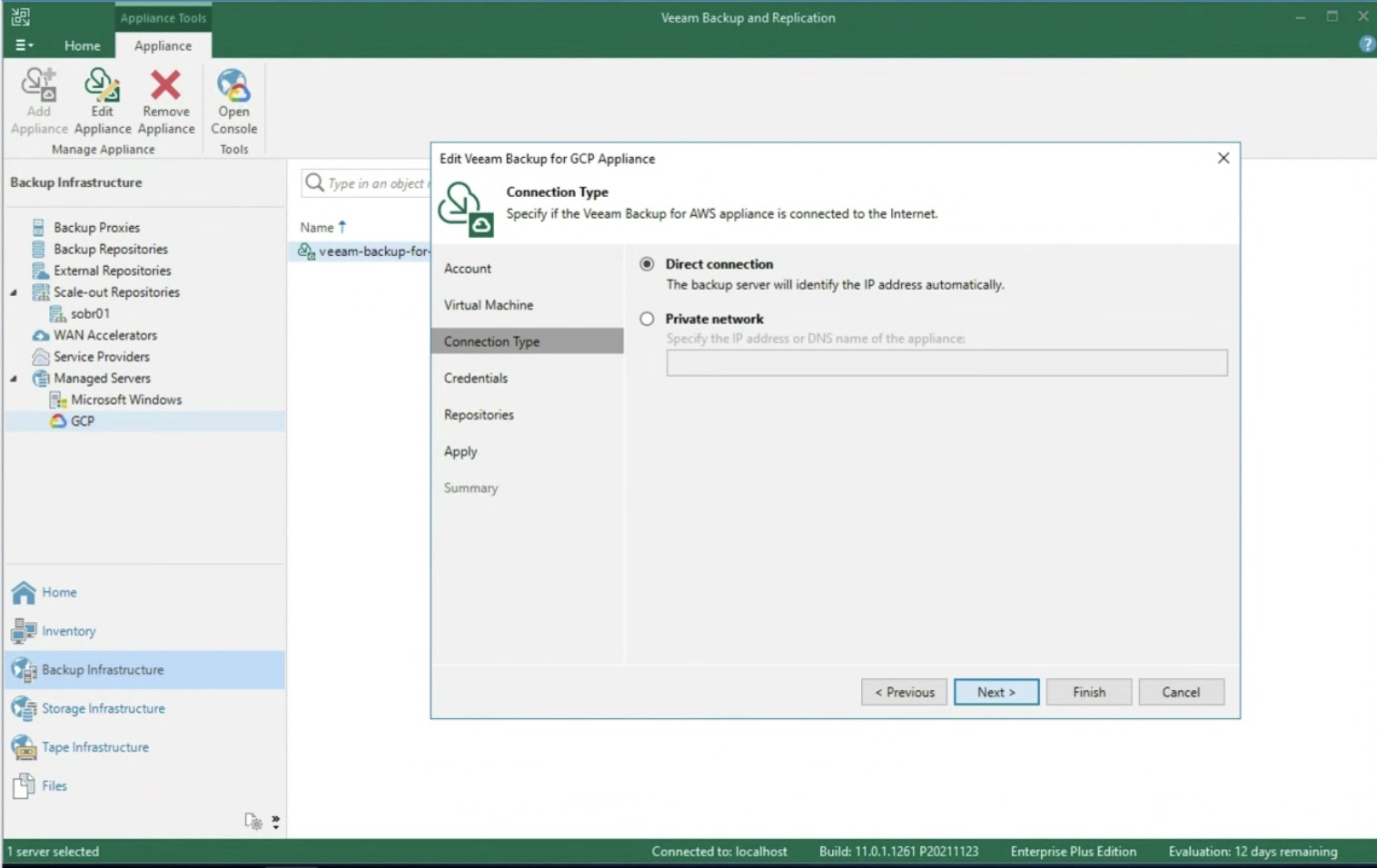 Immagine 5
Immagine 5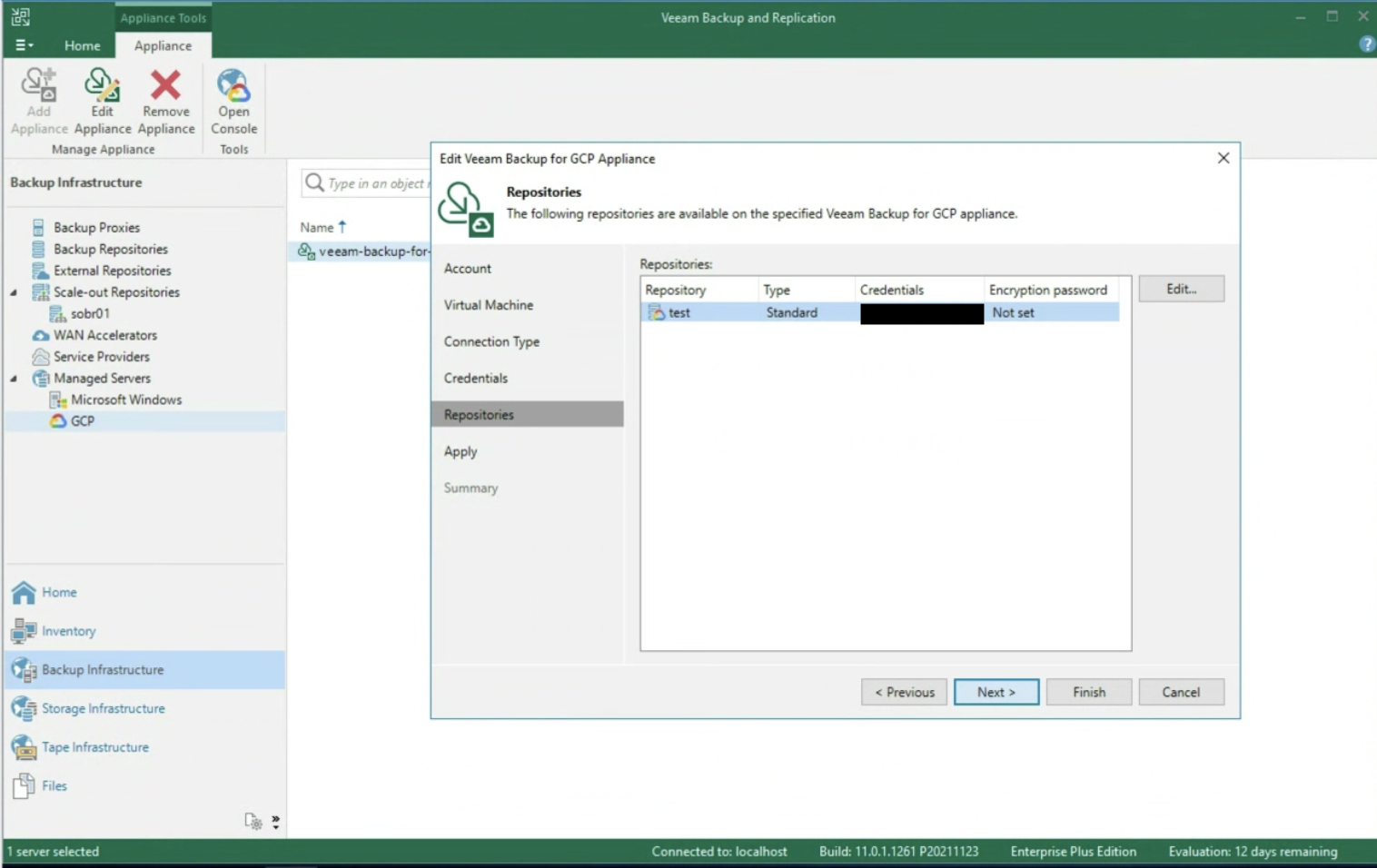 Immagine 6
Immagine 6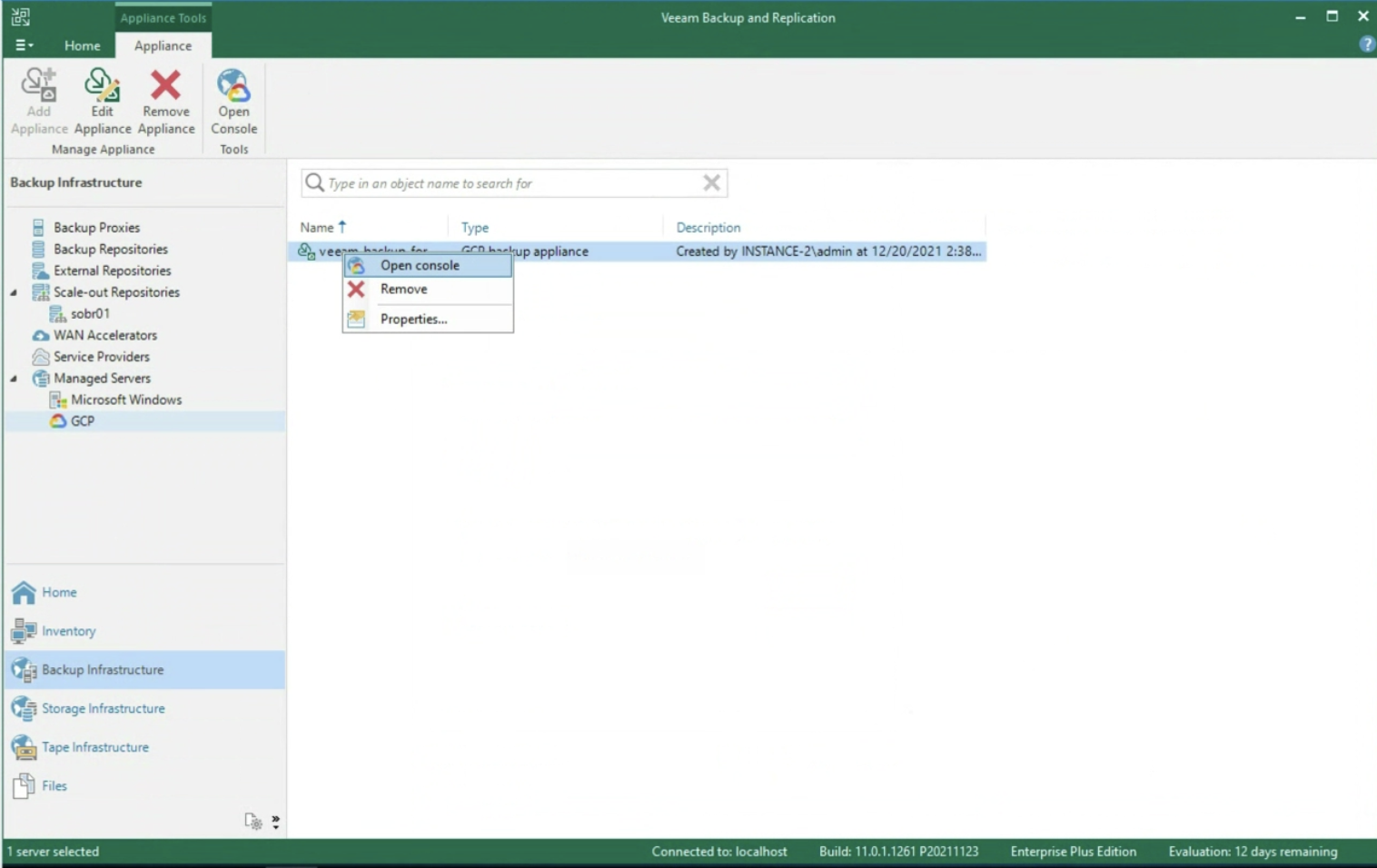 Immagine 7
Immagine 7 Immagine 8
Immagine 8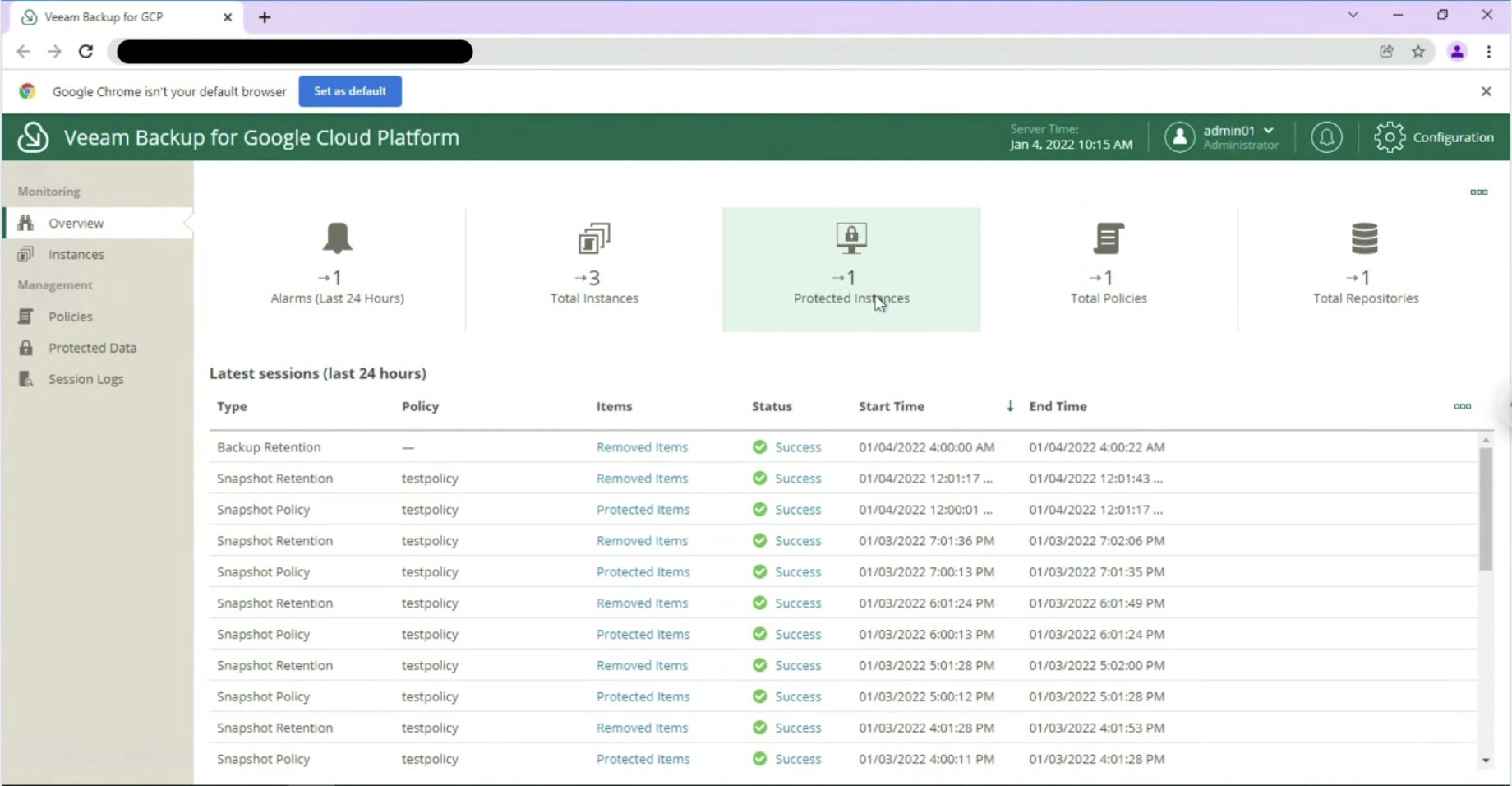 Immagine 9
Immagine 9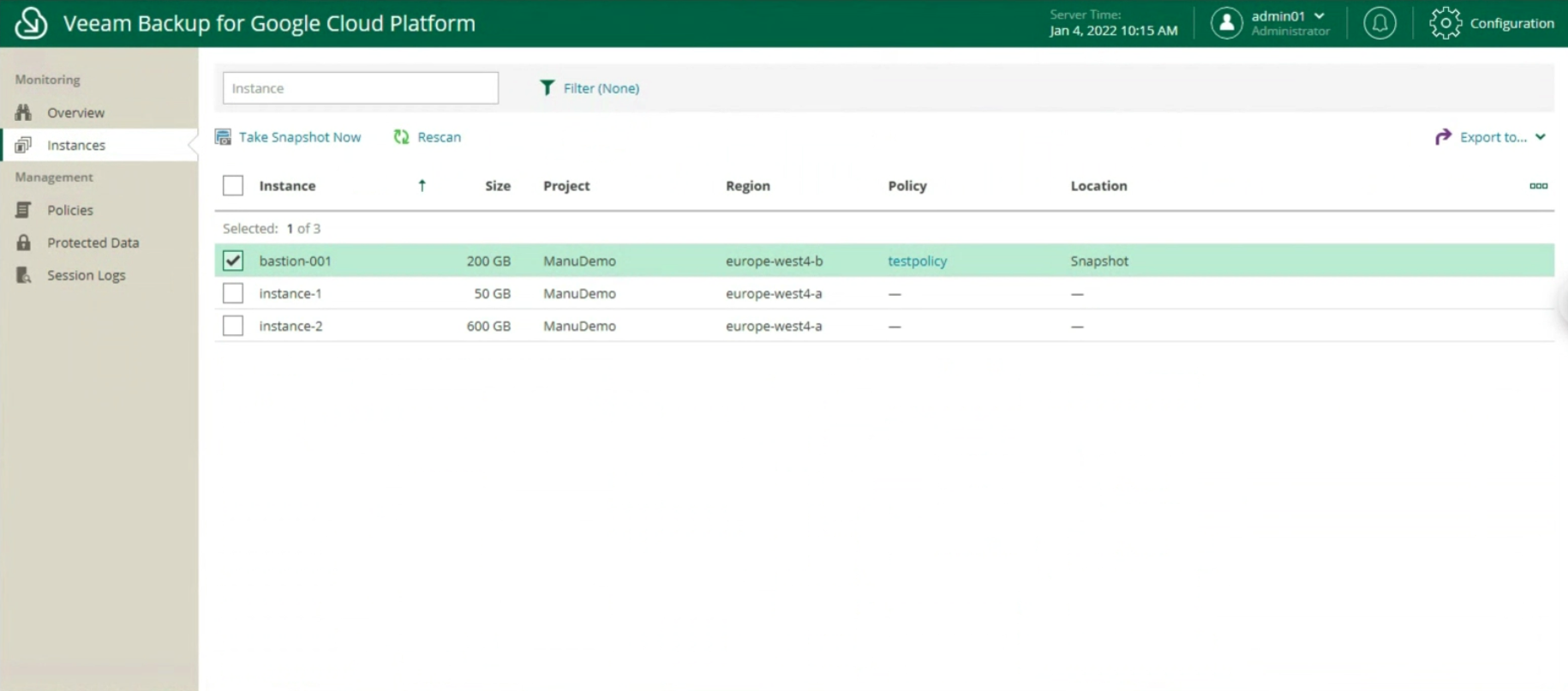
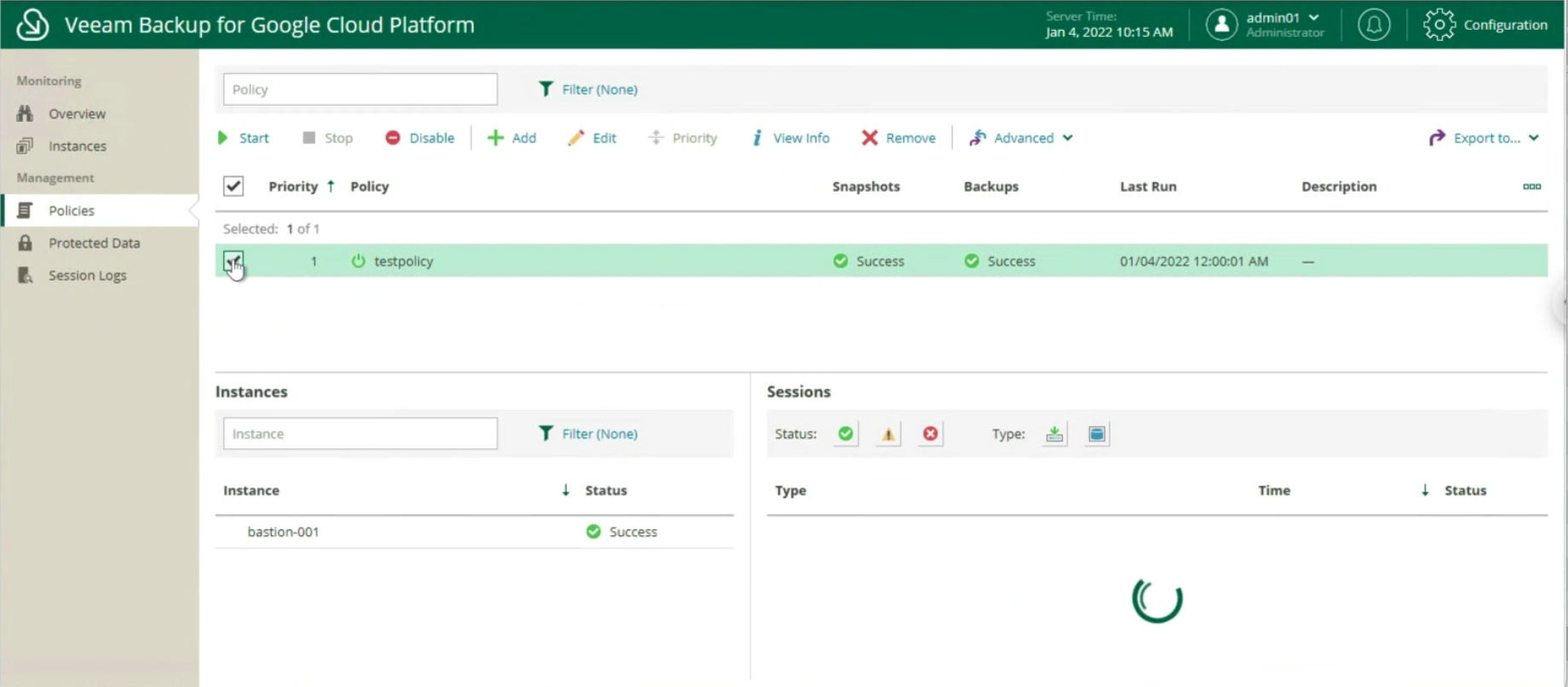 Immagine 11
Immagine 11 Immagine 12
Immagine 12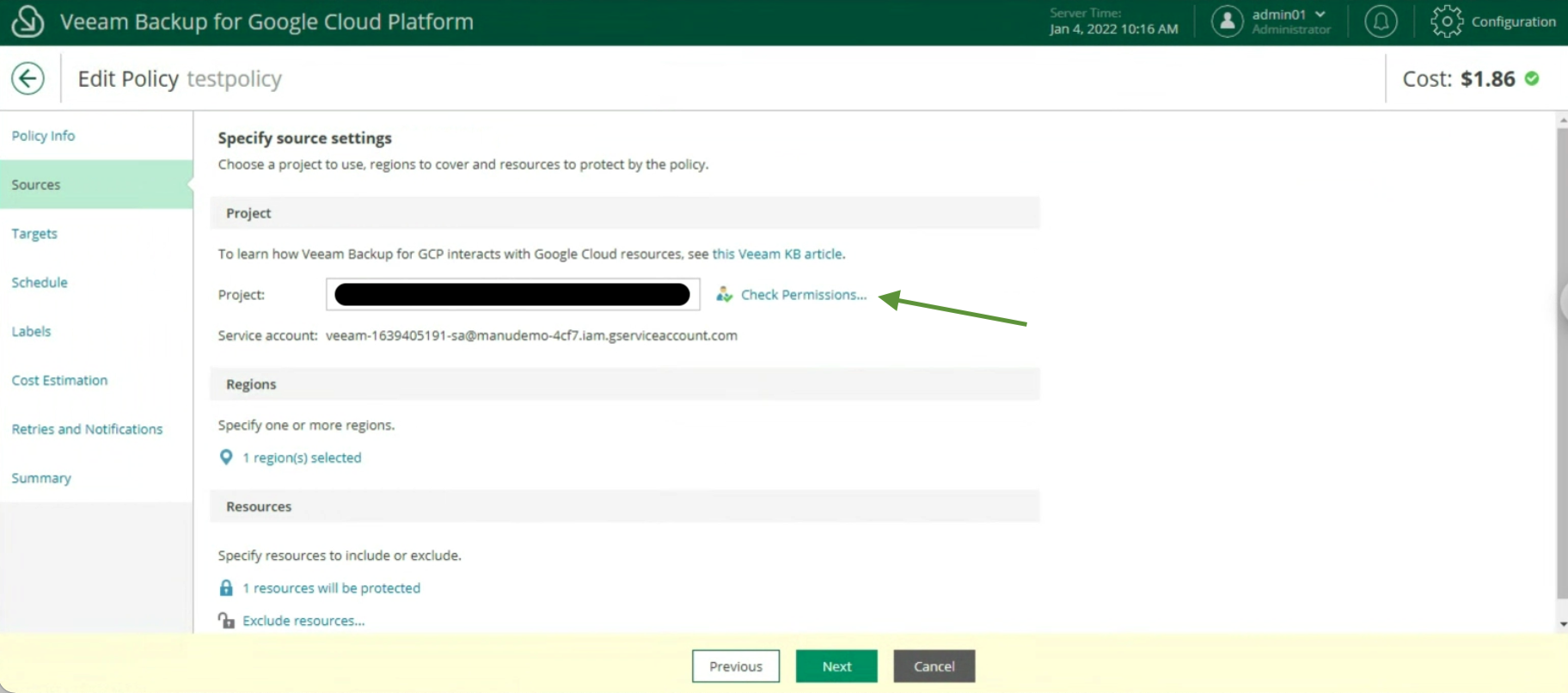 Immagine 13
Immagine 13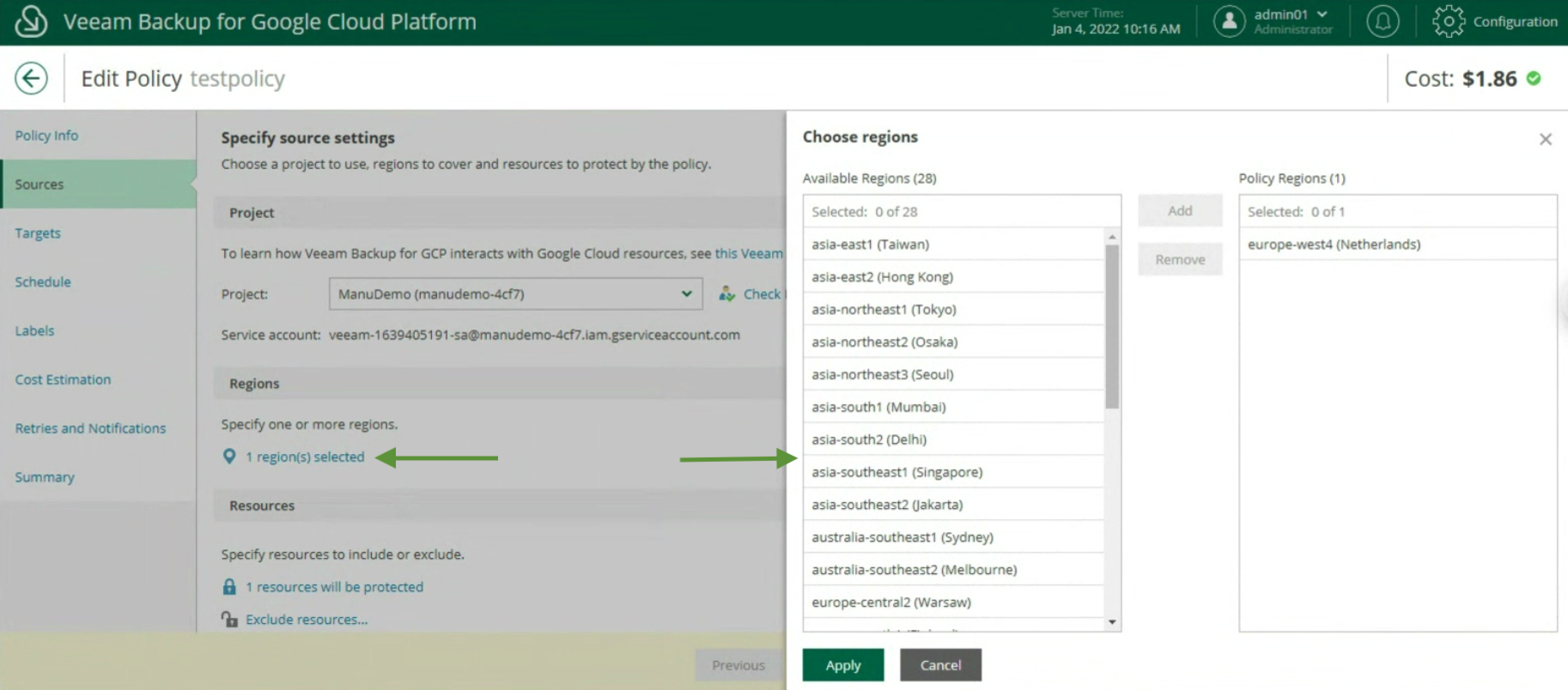 Immagine 14
Immagine 14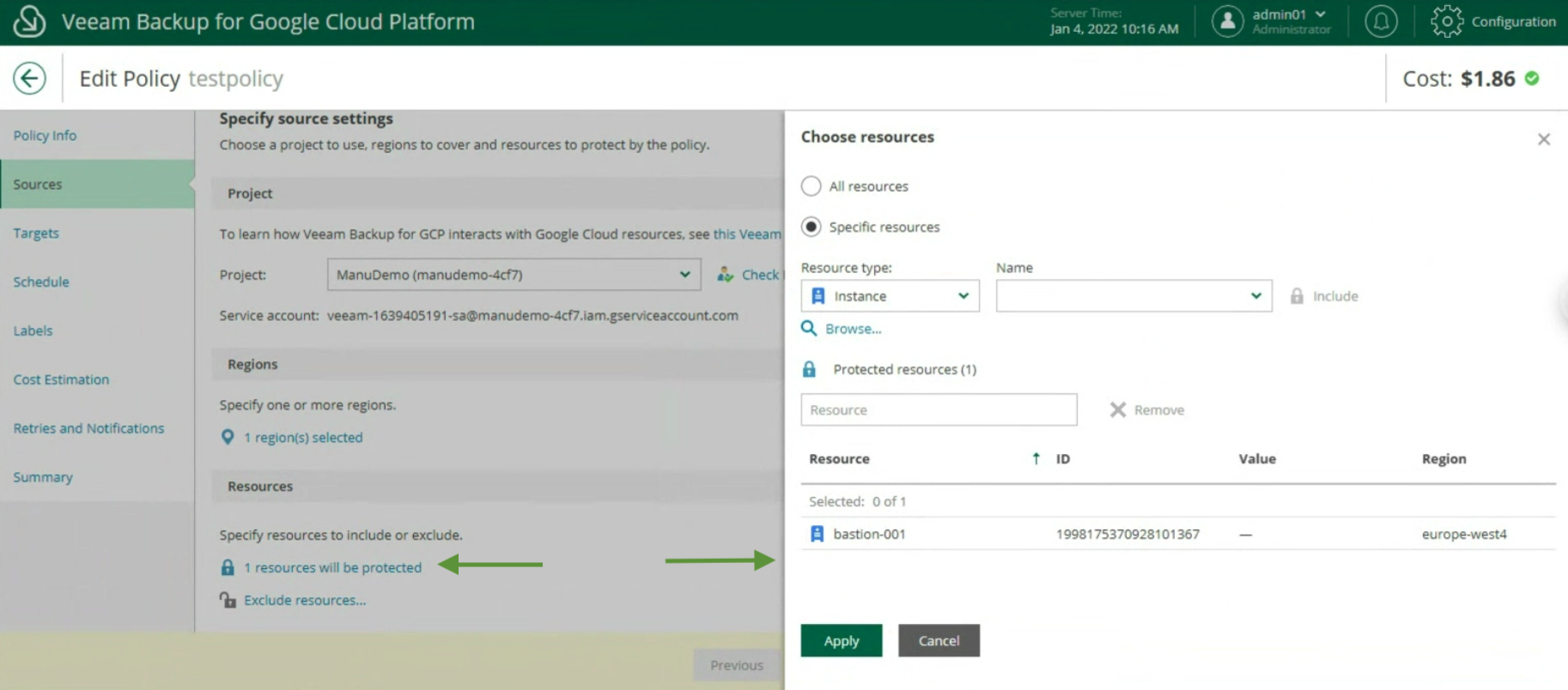 Immagine 15
Immagine 15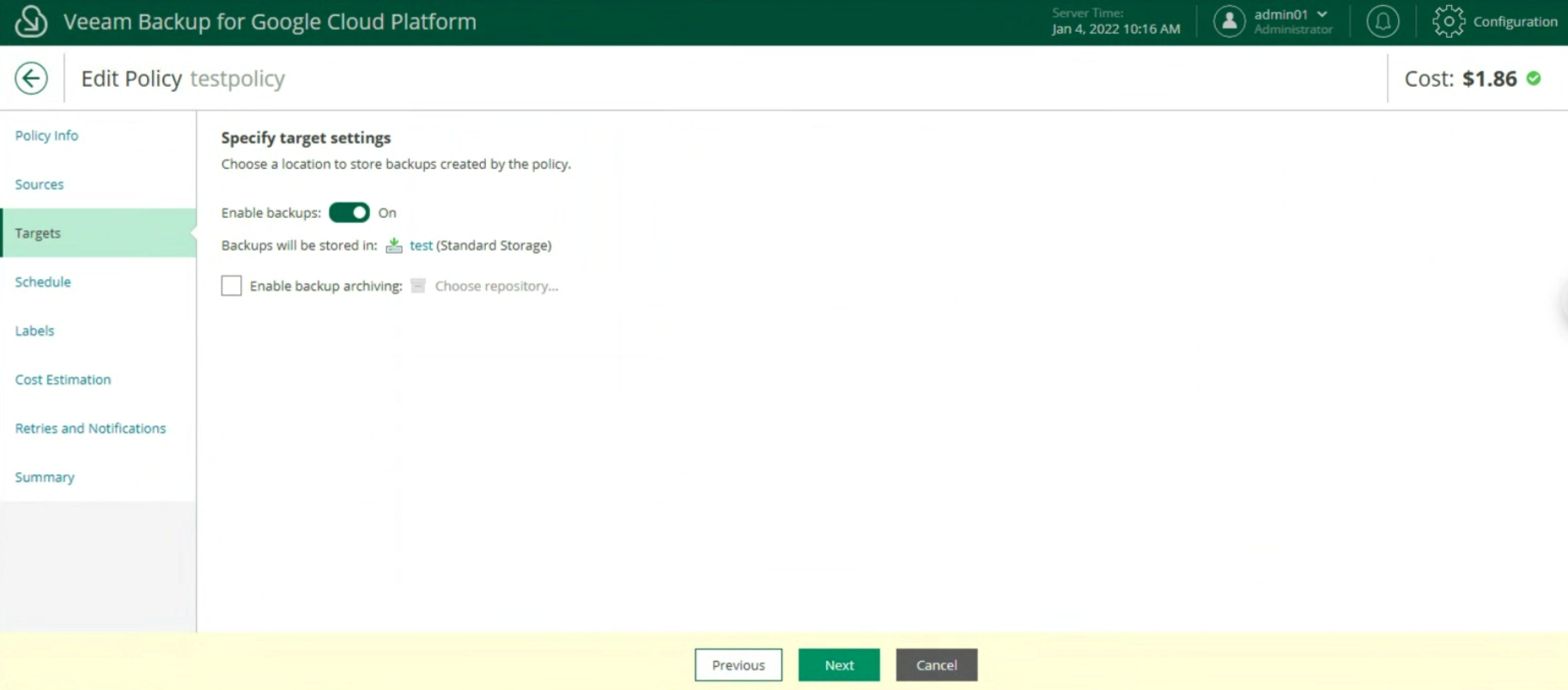 Immagine 16
Immagine 16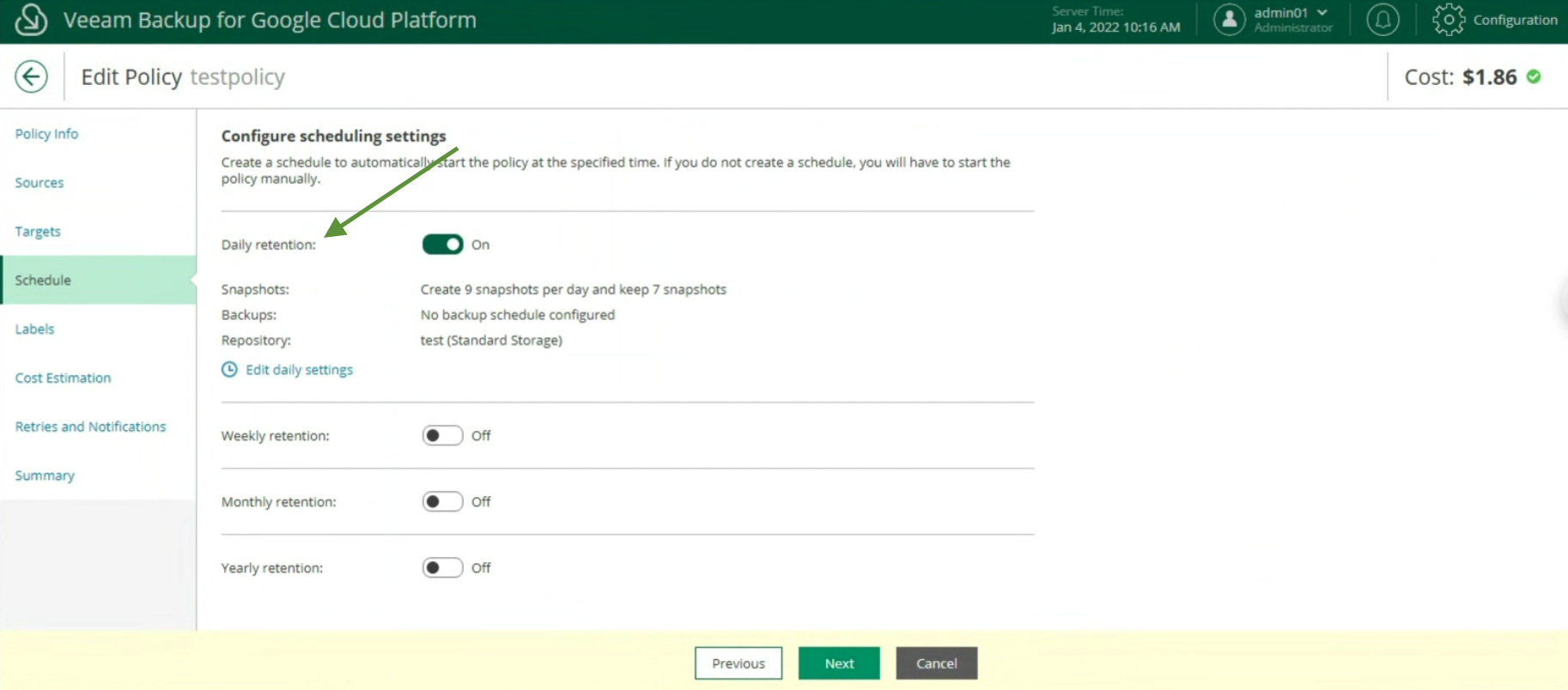 Immagine 17
Immagine 17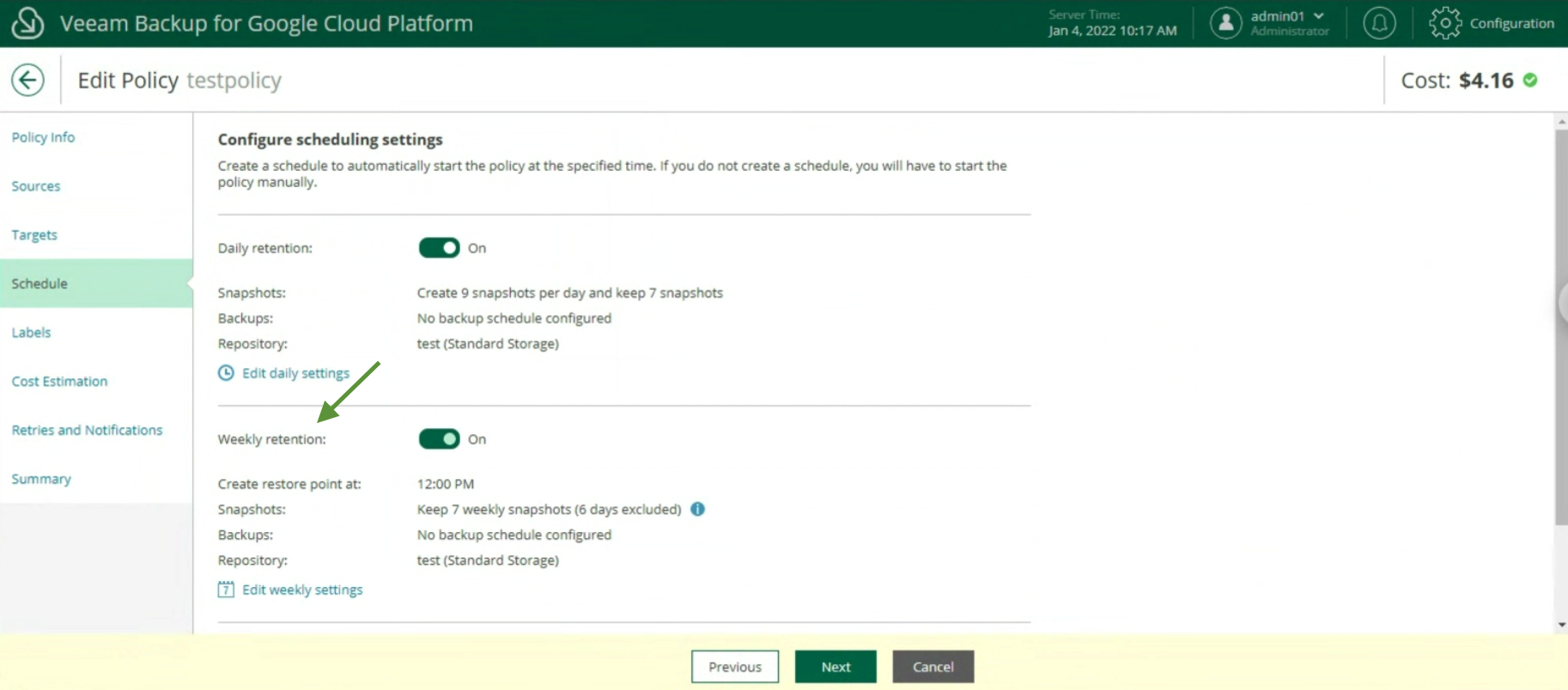 Immagine 18
Immagine 18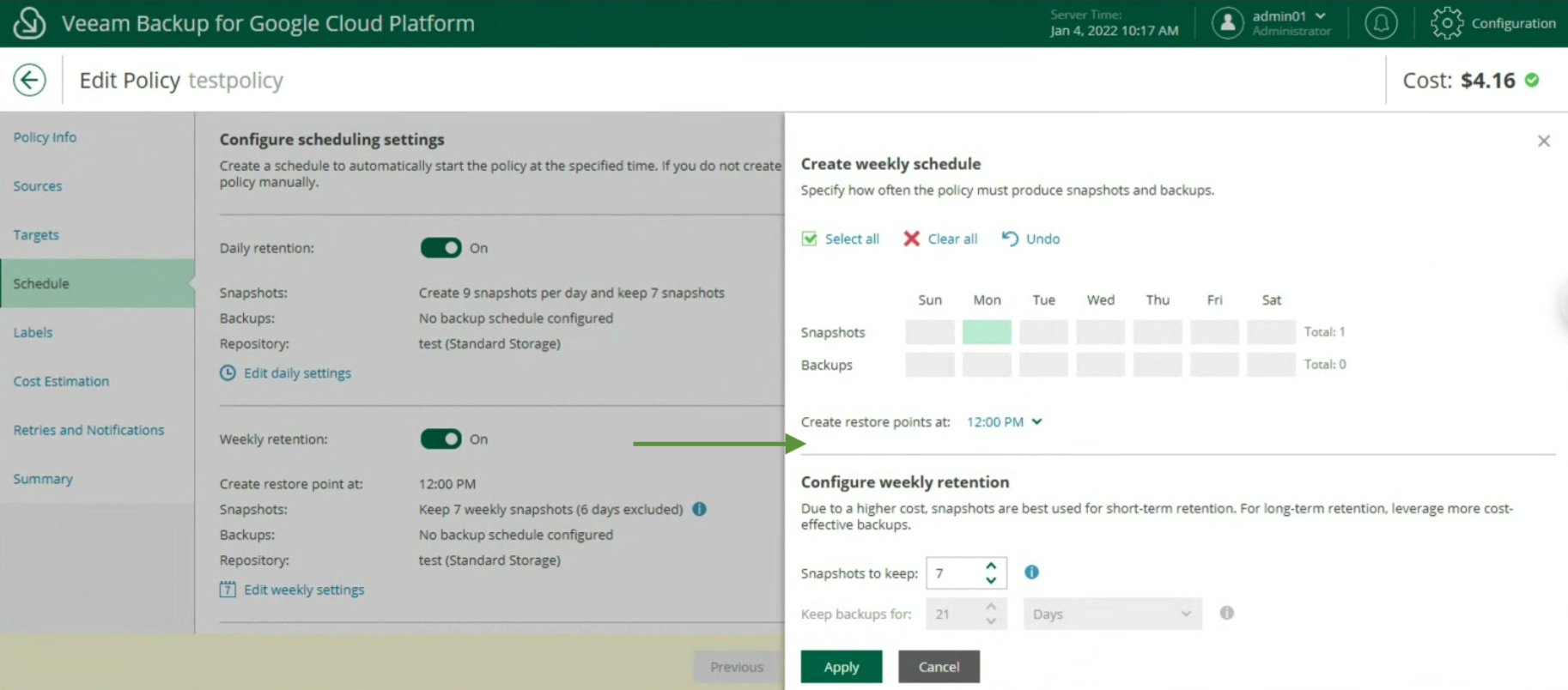 Immagine 19
Immagine 19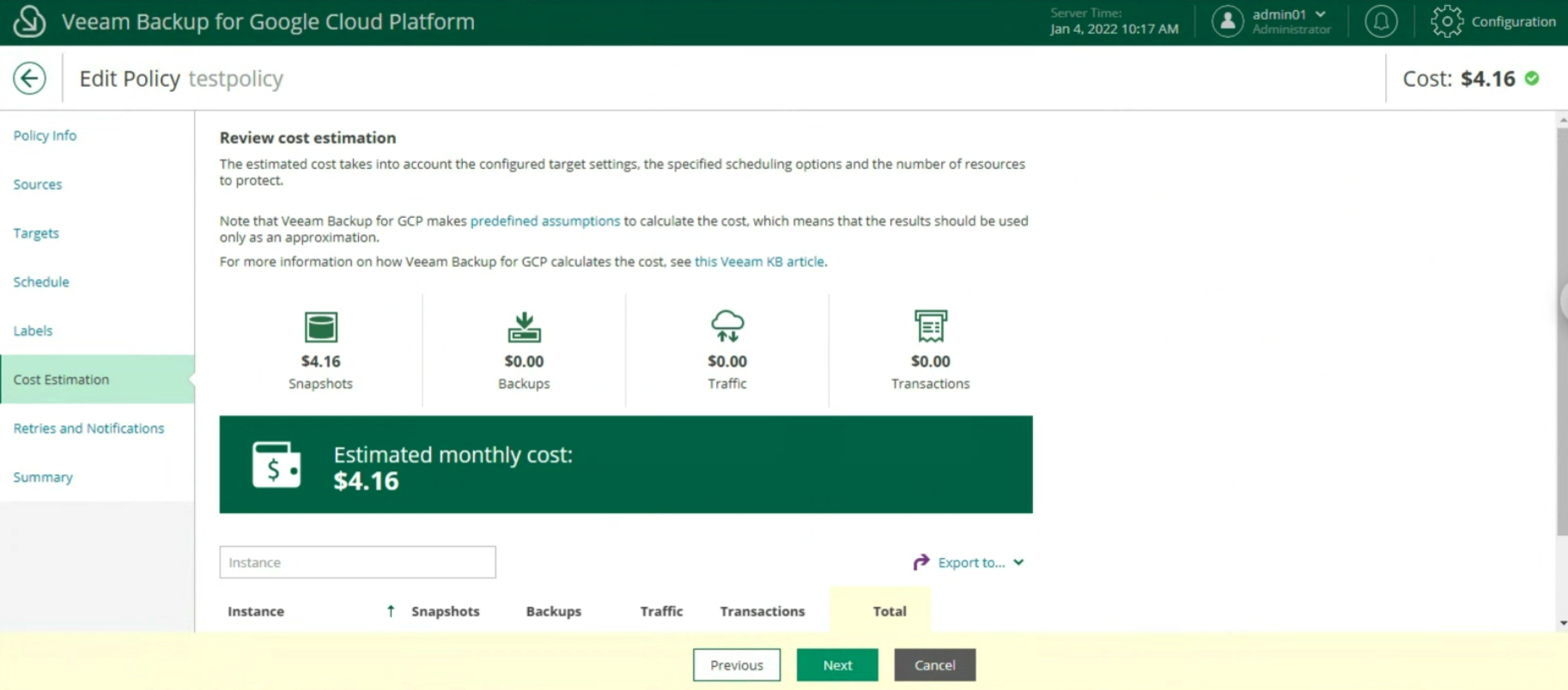 Immagine 20
Immagine 20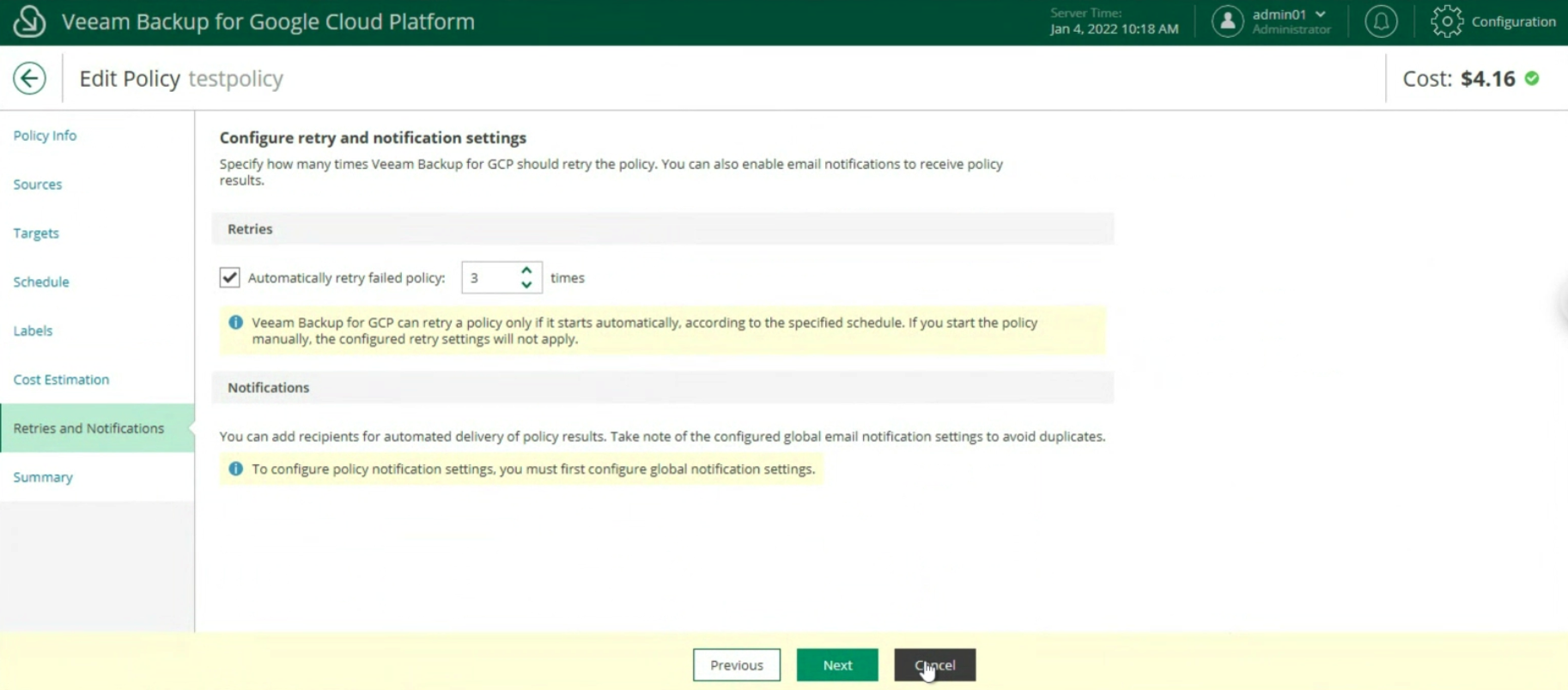 Immagine 21
Immagine 21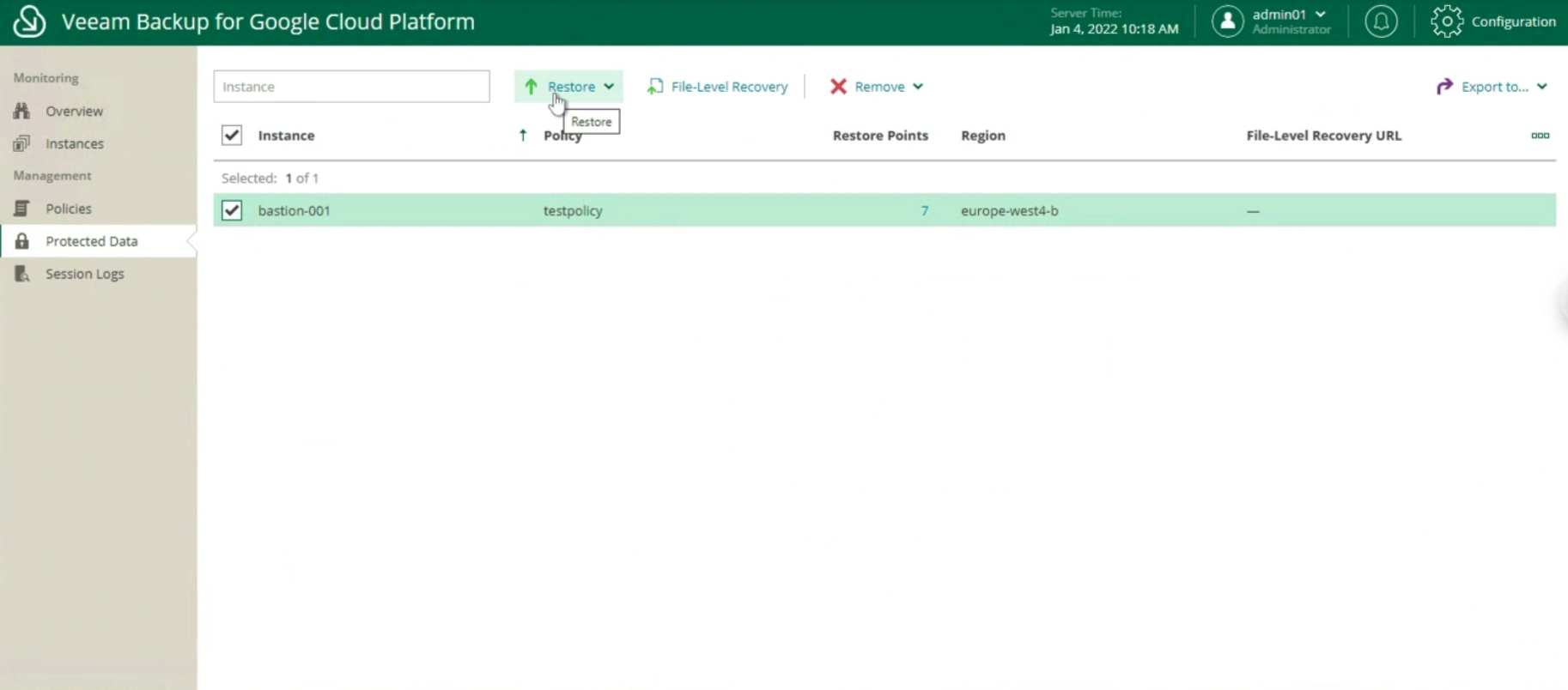 Immagine 22
Immagine 22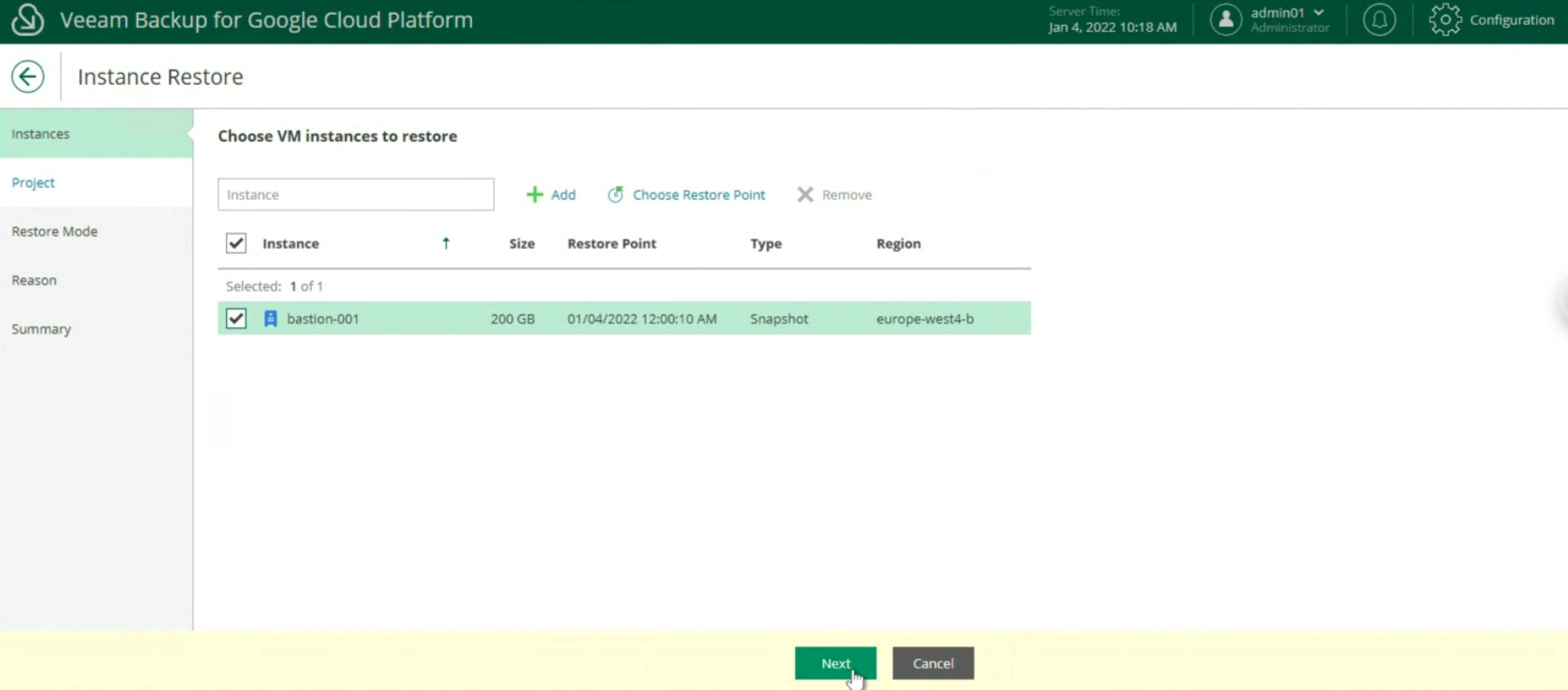 Immagine 23
Immagine 23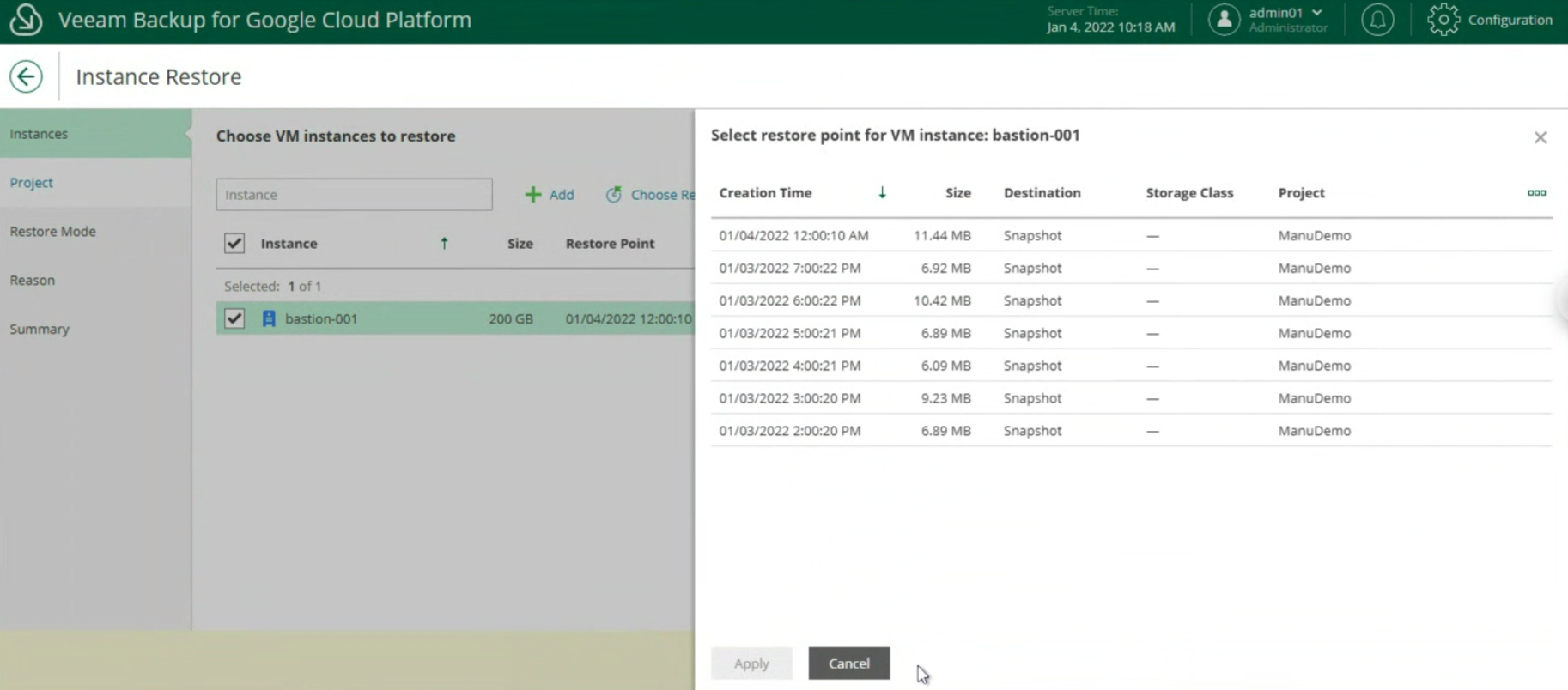 Immagine 24
Immagine 24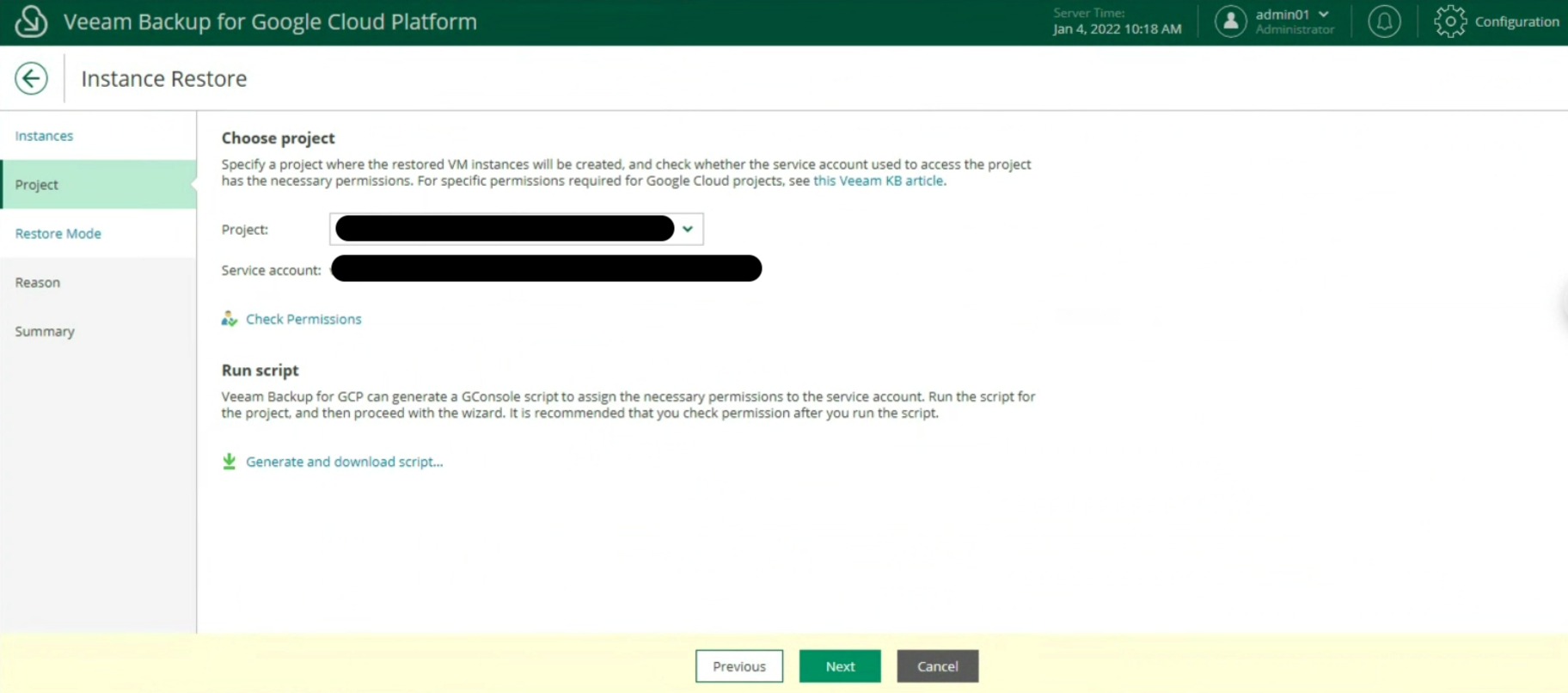 Immagine 25
Immagine 25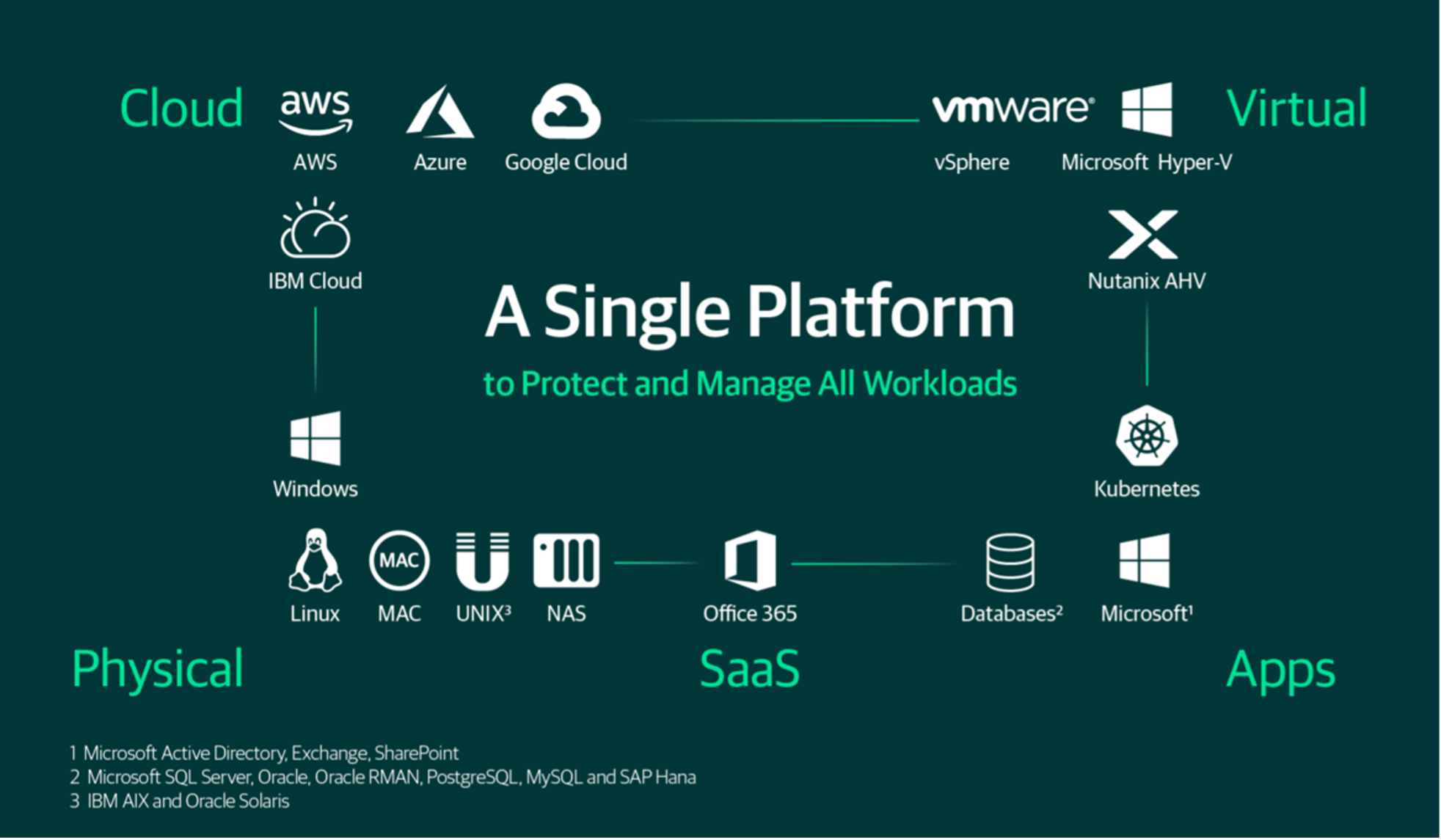
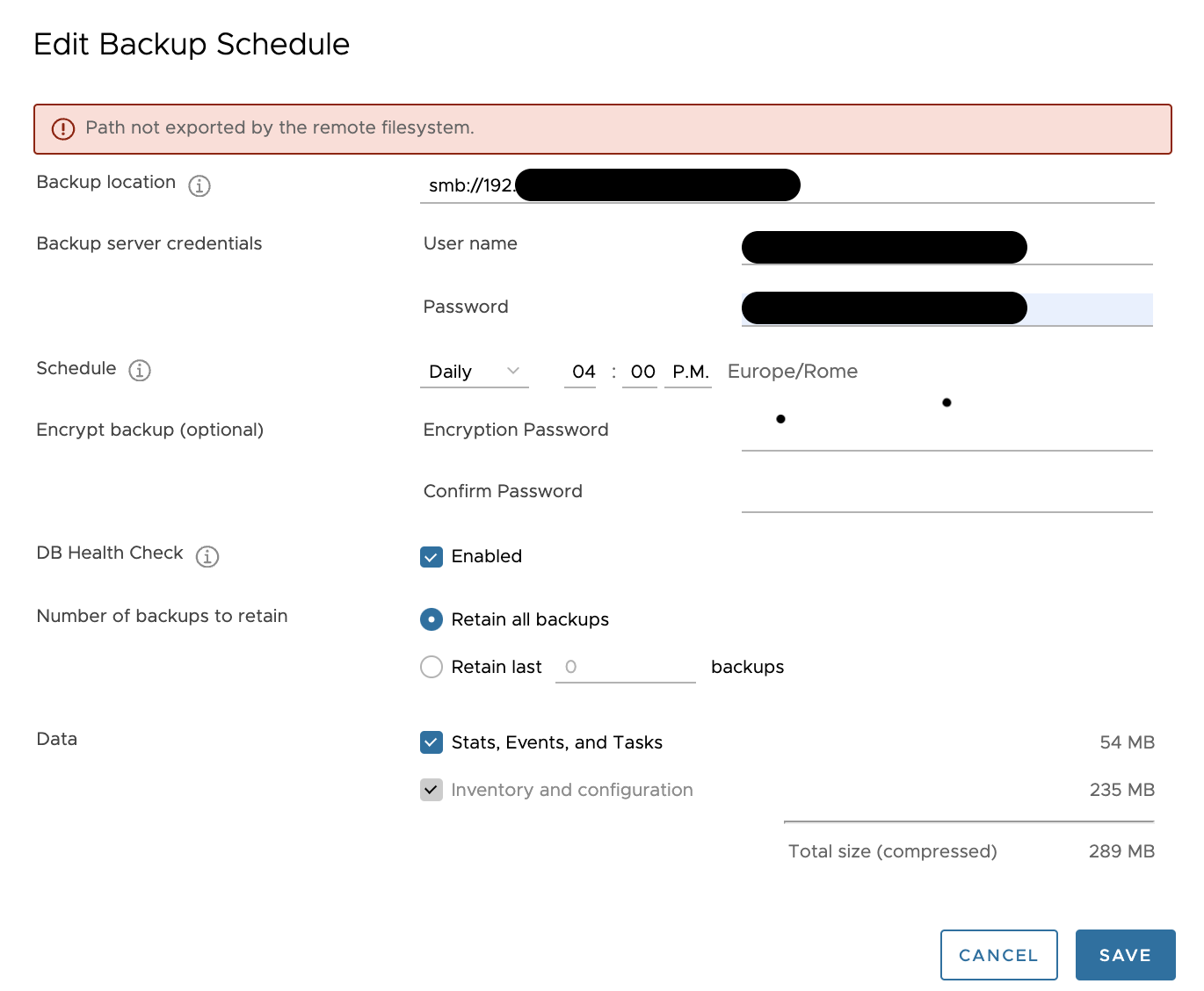 Immagine 1
Immagine 1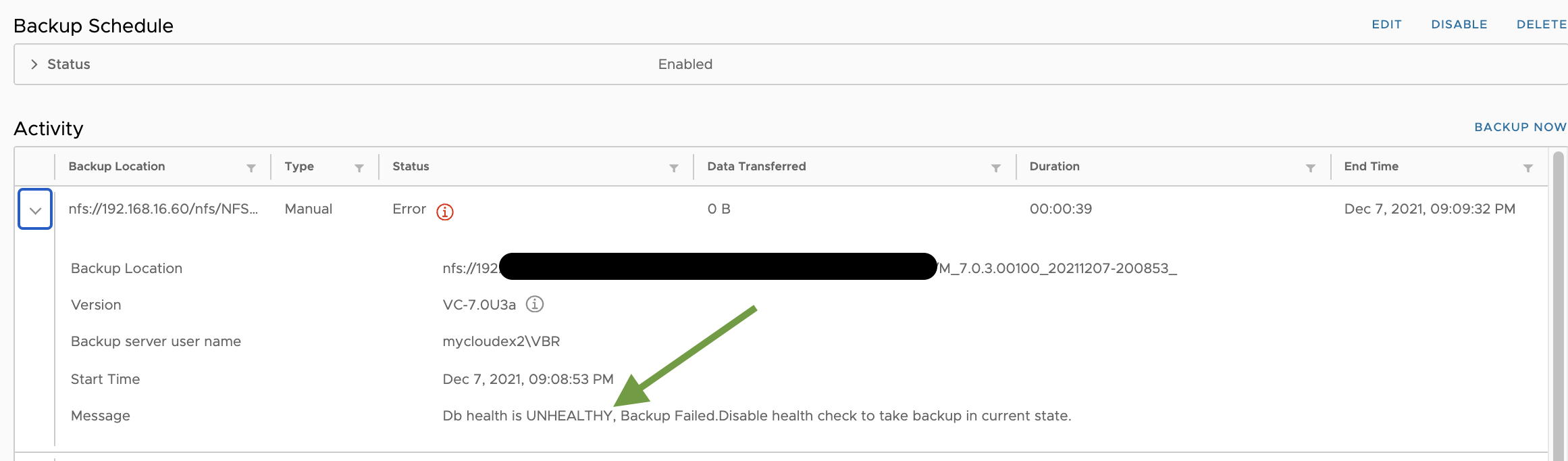 Immagine 2
Immagine 2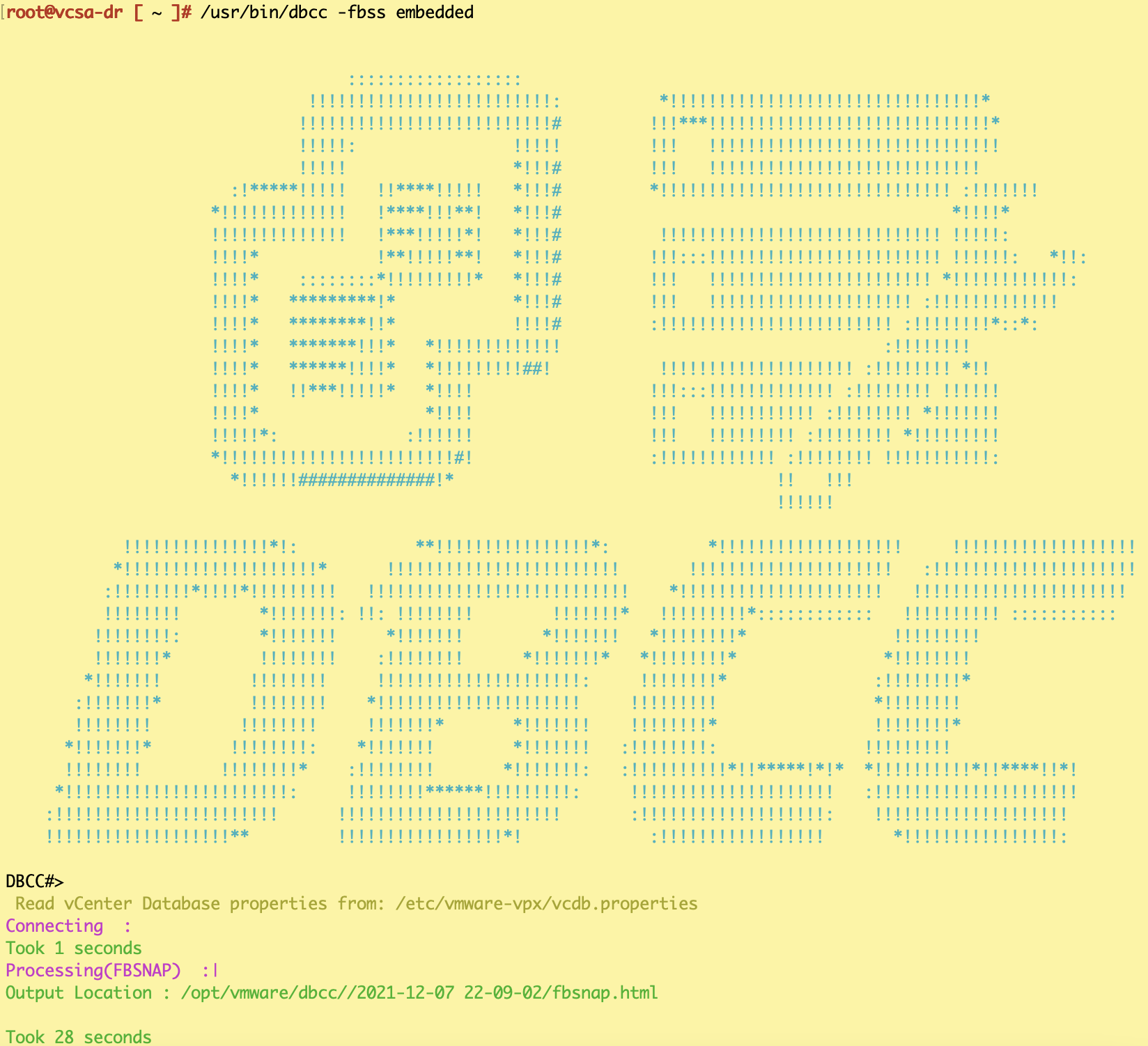 Immagine 3
Immagine 3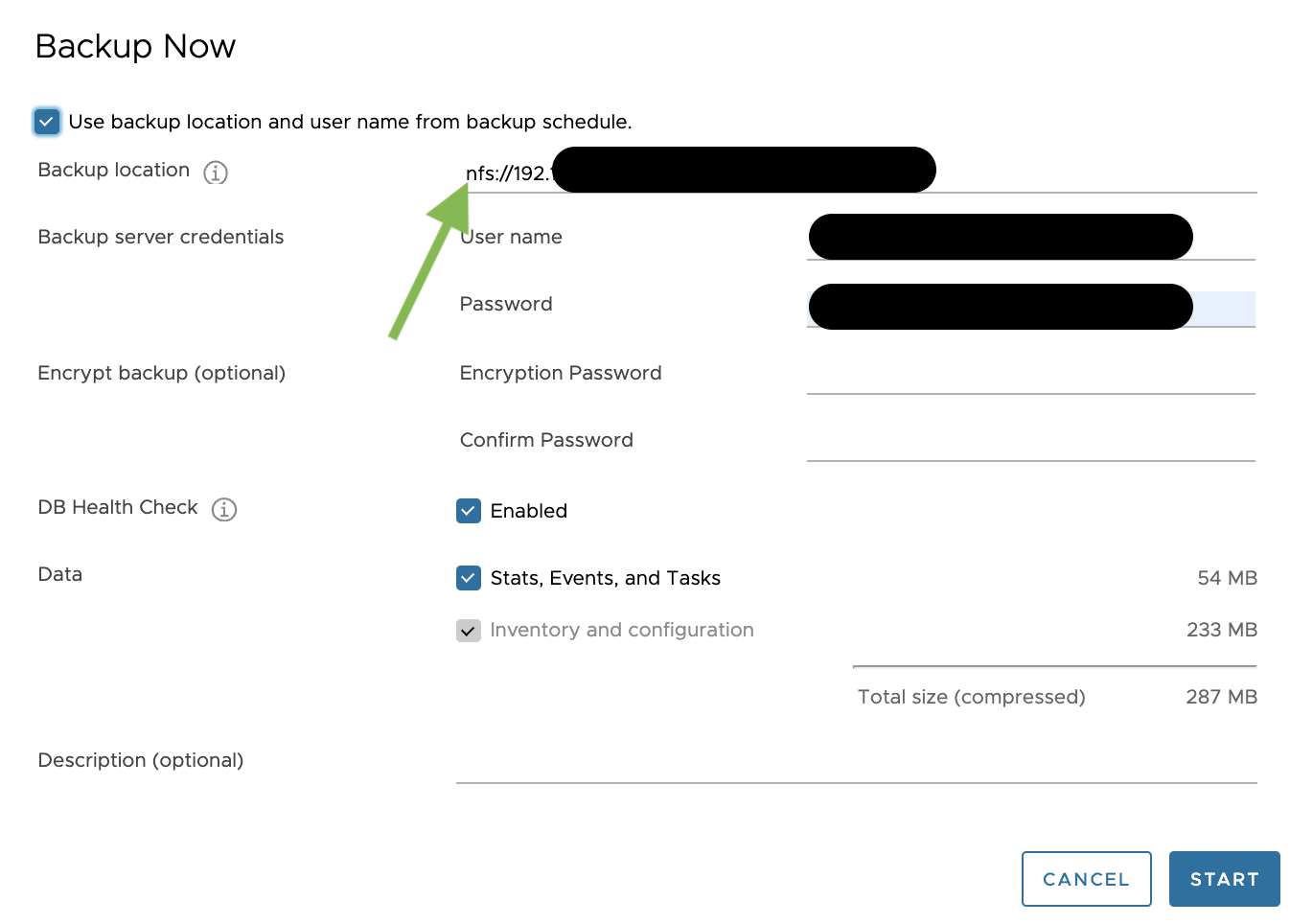 Immagine 4
Immagine 4 Immagine 5
Immagine 5