The topic of this article is understanding how to automatize the delivery of a micro-service.
In the previous one, I showed the flow process of a service. This flow requires typing a lot of commands to launch any single container.
Is there a way to automatize the entire process making it easier?
Yes, Docker-compose is a tool for defining and running an environment multi-container.
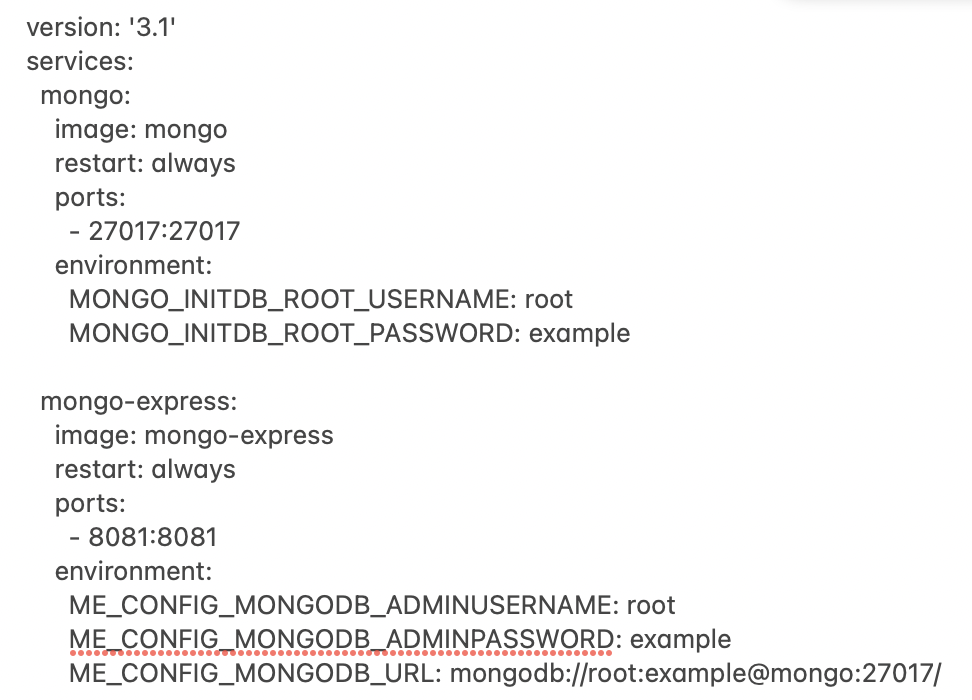
Docker-compose works with a describing file that includes all the configurations. The file has the extension YAML (human-readable data-serialization language).
After writing the YAML file (in this example it is named mypersonalfile.yaml), the syntax of the command is:
docker-compose -f mypersonalfile.yaml
Let’s see an easy example using the article I wrote in the last episode as a source.
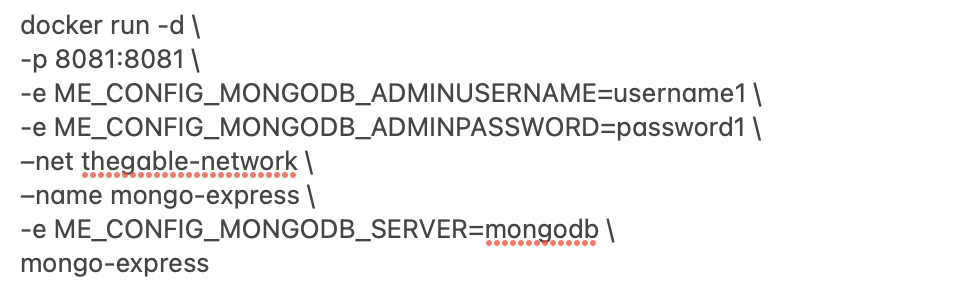
I had to type all these commands to implement the service:
a. Mongo DB commands
b. Mongo Express commands
In their place, it’s possible to use the following yaml file.
mypersonalfile.yaml
We will find yaml files again when writing about Kubernetes architecture and its protection.
The first two articles explained what a container is (article 1) and how they can talk to each other (article 2).
In this third article, I’m going to show how to deploy a service through this new and amazing container technology.
Note 1: I won’t cover the image flow deployment part (Git – Jenkins, Docker repository, and so on) because my goal is to explain how to implement a service, not how to write lines code.
Main Point:
As many of you already know, a service is a logical group of applications that talk to each other
Every single application can run as an image
Any image can run to a container
Conclusion: Deploying container technology is possible to build up any service
An example could clarify the concept.
Example: Web application
A classical web application is composed of a Front-End, a Back-End, and a DB.
In the traditional world, every single application runs on a single server (virtual or physical it doesn’t matter).
This old scenario required to work with every single brick of the wall. It means that to design correctly the service the deployers and engineers have to pay attention to all the objects of the stack, starting from OS, drivers, networks, firewall, and so on.
Why?
Because they are a separate group of objects that need a compatibility and feasibility study to work properly together and they require great security competencies also.
Furthermore, when the service is deployed and every single application is going to be installed, it often happens that remote support from the developer team is required. The reason is that some deployment steps are not clear enough just because they are not well documented (developers are not as good at writing documentation as they are at writing codes). The result is that opening a ticket to customer service is quite normal.
Someone could object and ask to deploy a service just using one server. Unfortunately, it doesn’t solve the issue, actually, it amplifies it up just because in that scenario, it’s common to meet scalability problems.
Let’s continue our example by talking about the architecture design and the components needed (Picture 1)
Front End: HTML and JavaScript
Back End: Node.js: It is a framework, which is used to write server-side Javascript applications (https://nodejs.org/it/)
Note 2: In the next rows, I will skip how to deploy the front and backend architecture as well as the docker technology because:
Writing HTML and Javascript files for creating a website is quite easy. On Internet, you can find a lot of examples that will meet your needs.
Node.js is a very powerful open-source product downloadable from the following website where it’s possible to get all the documentation needed to work with it.
Docker is open-source software; it can also be downloaded from the official open-source website. The installation is a piece of cake.
My focus here is explaining how to deploy and work with docker images. Today’s example is the Mongo DB and Mongo Express applications.
I wrapped up the steps in 4 main stages:
a. First point: Creating a Network
It allows communication from and to the images.
In our example, the network will be named “thegable-network”.
From the console (terminal, putty….) just run the following commands:
b. Download from docker hub the images needed
c) Running the mongo DB image with the correct settings:
d) Run the mongo-Express image with the correct settings:
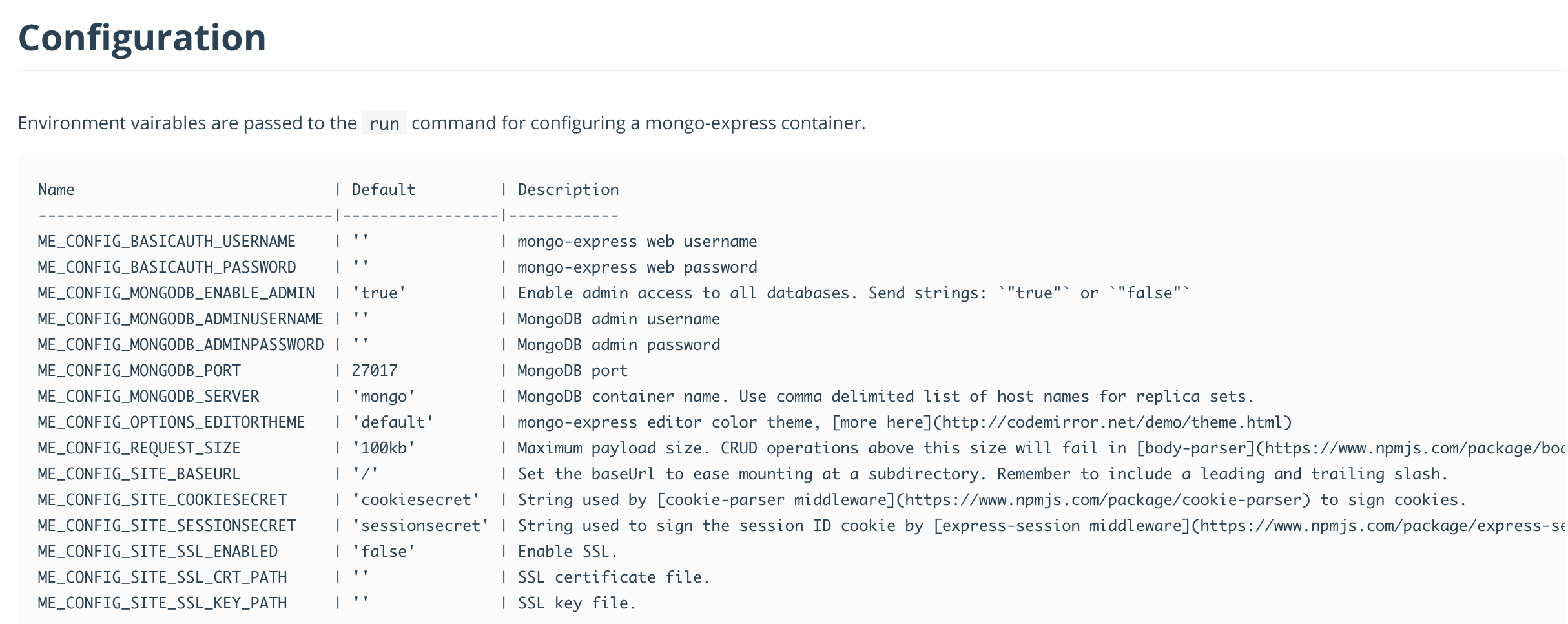
Note 3: The configurable settings are available directly from the docker images.
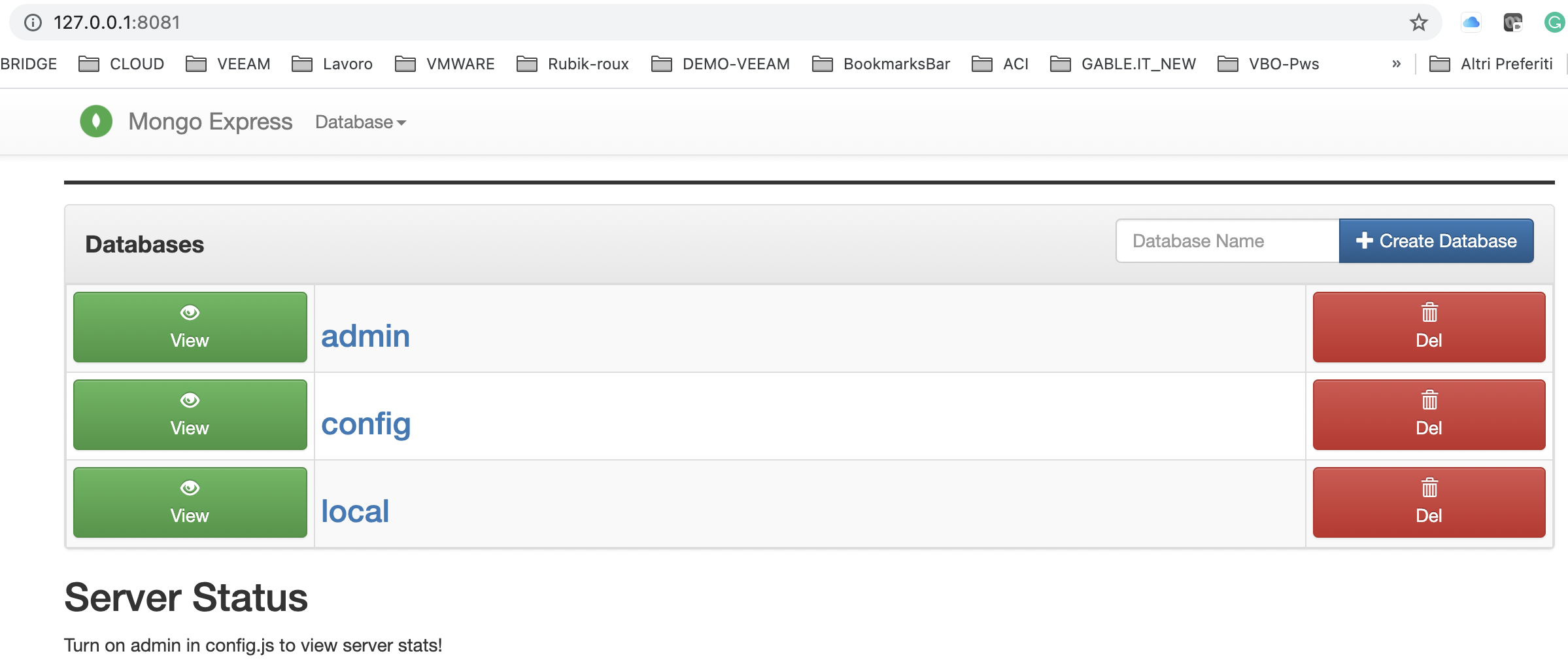
Connecting to the main web page of mongo-express (localhost: port), have to appear the mongo default Databases as shown in picture 3
Picture 2
Now creating new Mongo DBs (through the Mongo-Express web interface just for example create the DB named “my-GPDB“) and managing your javascript file, it’s possible to build up your own web application.
In the javascript file (normally is named server.js) the main points to connect to the DB are:
(Please refer to a javascript specialist to get all details needed)
Is it easy? Yes, and this approach allows having a fast and secure deployment.
In just a word, it is amazing!
That’s all folks for now.
The last article of this first series on modern applications is Docker Compose
As written in the last article a container can manage more images.
Picture 1 shows an example of three different workloads running in a single container.
Picture 1
It’s possible to work with different versions of the same image also.
For example, MySQL has several images that can be installed and run to the same container.
Note 1: Nowadays MySQL available images are:
8.0.25, 8.0, 8, latest
5.7.34, 5.7, 5
5.6.51, 5.6
Picture 2 shows a container where three different images run with two kinds of version applications.
Picture 2
Let’s digress slightly talking about how a service is built.
Most of the time it is made by grouping applications that means grouping several types of images.
The question is: How do images talk to each other?
The answer is quite easy. They talk through the networks, where IP addresses and ports are in charge of the communication to and from the applications (picture 3).
Picture 3
There is just a simple rule to remember when a container network architecture is deployed.
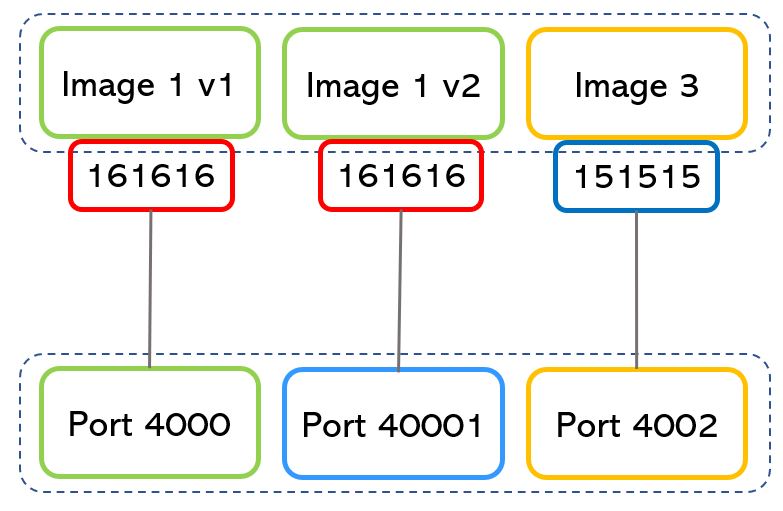
As shown in picture 4, if the ports used by a running image can be the same for different applications (in example 161616), the port assigned to the back-end server must be always different (4000,40001,4002).
Note 2: The port numbers are just an example also because the port with the higher number is 216 = 65535.
Picture 4
Wrap-up: The binding network architecture is completely allowed but the host back-end port can’t expose the same port number to more than one service.
Let’s go deeper into networking in the Container environment:
The network’s topology is defined by the used drivers.
They can be:
1. Host
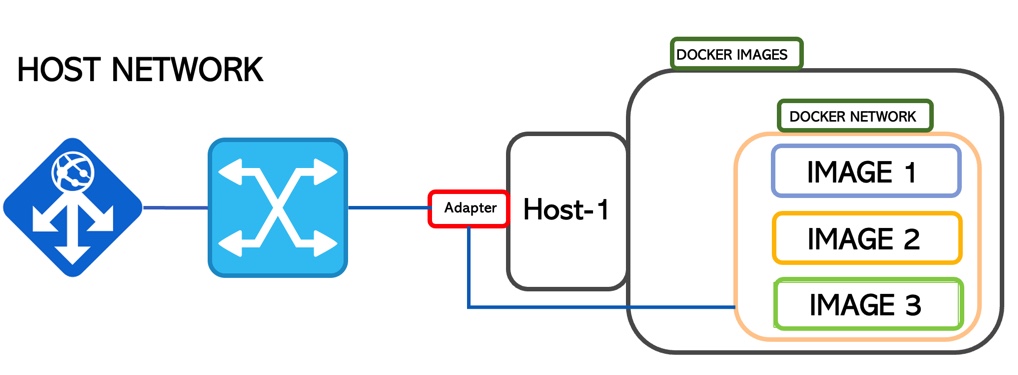
When the container comes up it attaches its ports to the host network directly.
In this way, it shares the TCP/IP stack and the Host NameSpace.
The segregation is guaranteed by Docker technology (Picture 5)
Picture 5
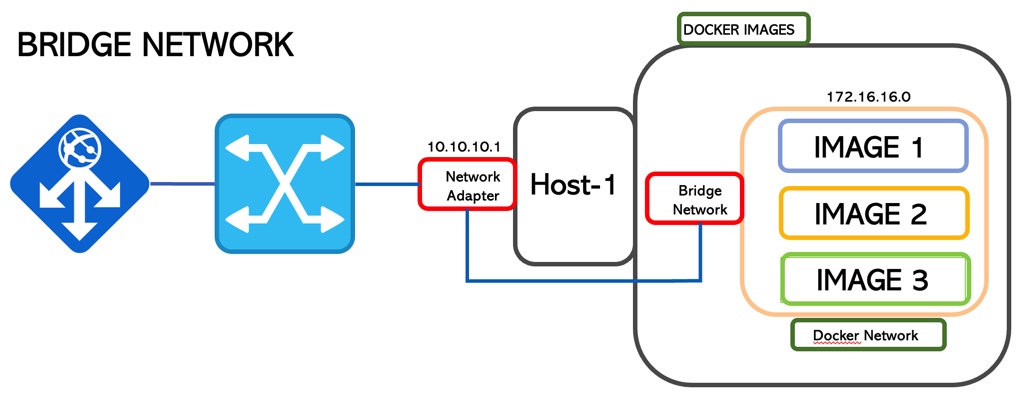
2. Bridge
This is the default network mode.
It creates an isolated bridge network where the containers run inside a range of IP addresses.
In the previous scenario, the containers can talk to each other but no connection is allowed from outside.
To allow communication with external service in Docker, it’s necessary to start docker with the -p option.
docker run -pserverport:containerport nameservice (ie: docker run -p2400:2451 mysql)
port 2400 is now working with 2451
From a security point of view, it is amazing. You can monitor and select which ports are going to be used for a service (Picture 6)
Picture 6
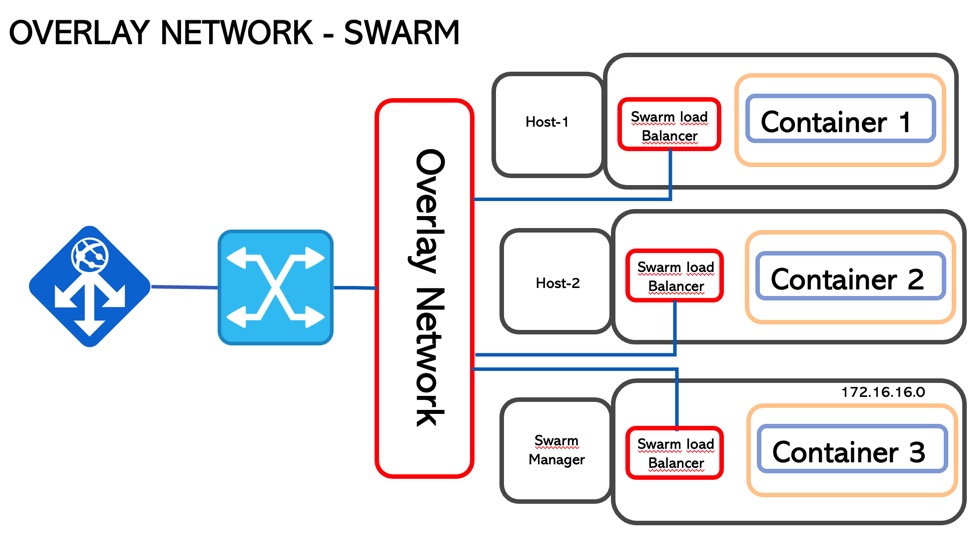
3. Overlay
If the previous technologies are single-host networking topology, the Overlay allows communication among the container hosted in different hosts.
This scenario requires cluster intelligence to manage the traffic and guarantee segregation. It could be Swarm or Kubernetes (picture 7)
The technology core that allows it is vxlan that creates a tunnel on top of the underlay network and it is part of the operating system
The traffic is encrypted (AES) with a rotating password.
When a service is exposed (-p option wrote before), all traffic is automatically routed, nevermind where the service is running
More interesting details: each container has two IP addresses: the first one insists on the overlay network and is used by the containers to talk to each other (internal). The second address is for vxlan and allows the traffic to outside.
Picture 7
4. Null (Black box)
No network connection
5. MacVLan
It’s possible to implement a MacVLan through a driver. The scope is giving to the network container the behaviour of a traditional network. It’s necessary that the network accepts the promiscuous mode.
Se negli ultimi 5 anni, la parola Cloud è stata quella più utilizzata (anche in modo inappropriato), negli ultimi cinque mesi la parola che sta rieccheggiando di più nel mondo IT è Digital Transformation.
Da Wikipedia:
“Digital Transformation (DT o DX) è l’adozione della tecnologia digitale per trasformare servizi e aziende, sostituendo processi non digitali o manuali con processi digitali o sostituendo la tecnologia digitale precedente con la tecnologia digitale più recente”.
Ancora: la Digital Transformation deve aiutare le aziende ad essere più competitive attraverso la rapida implementazione di nuovi servizi sempre in linea con le esigenze aziendali.
Nota 1: La trasformazione digitale è il paniere, le tecnologie da utilizzare sono le mele, i servizi sono i mezzi di trasporto, i negozi sono i clienti/clienti.
1. Tutte le architetture IT esistenti possono funzionare per la Trasformazione Digitale?
Preferisco rispondere ricostruendo la domanda con parole più appropriate:
2. La trasformazione digitale richiede che dati, applicazioni e servizi si spostino da e verso architetture diverse?
Sì, questo è un must ed è stato nominato Data Mobility.
3. La Data-Mobility significa che i servizi possono essere indipendenti dall’infrastruttura sottostante?
La miglior risposta credo che sia: nonostante al giorno d’oggi non esista un linguaggio standard che permetta a diverse architetture/infrastruttura di dialogare tra loro (on-premises & on cloud), le tecnologie di Data-mobility sono in grado di superare tale limitazione.
4. La Data Mobility è indipendente dai fornitori?
Quando uno standard viene rilasciato, tutti i fornitori vogliono implementarlo al più presto perché sono sicuri che queste funzionalità miglioreranno le loro entrate. Attualmente, questo standard non esiste ancora.
Nota 3: penso che il motivo sia che ci sono così tanti oggetti da contare, analizzare e sviluppare che lo sforzo economico per farlo non è al momento giustificato
5. Esiste già una tecnologia Ready “Data-Mobility”?
La risposta potrebbe essere piuttosto lunga ma, per farla breve, ho scritto il seguente articolo che si compone di due parti principali:
Livello applicazione (contenitore – Kubernetes)
Livello dati (backup, replica)
Application Layer – Container – Kubernetes
Nel mondo IT, i servizi sono eseguiti in ambienti virtuali (VMware, Hyper-V, KVM, ecc.).
Vi sono ancora alcuni servizi che girano su architetture legacy (Mainframe, AS400 ….), (vecchi non significa che non siano aggiornati ma solo che hanno una storia molto lunga)
Nei prossimi anni i servizi verranno implementati in un’apposita “area” denominata “container”.
Il contenitore viene eseguito nel sistema operativo e può essere ospitato in un’architettura Virtuale/Fisica/Cloud.
Perché i contenitori e le competenze su di essi sono così richiesti?
a. L’esigenza degli IT Manager è quella di spostare i dati tra le architetture al fine di migliorare la resilienza e ridurre i costi. b. La tecnologia Container semplifica la scrittura del codice dello sviluppatore perché ha un linguaggio standard e ampiamente utilizzato. c. I servizi eseguiti sul container sono veloci da sviluppare, aggiornare e modificare. d. Il contenitore è “de facto” un nuovo standard che ha un grande vantaggio. Superare l’ostacolo della mancanza di standard di comunicazione tra le architetture (private, ibride e cloud pubblico).
Un approfondimento sul punto d.
Ogni azienda ha il proprio core business e tutte hanno bisogno della tecnologia informatica.
Qualsiasi dimensione dell’azienda?
Sì, basti pensare all’ uso del cellulare, per prenotare un tavolo al ristorante o acquistare un biglietto per un film. Sono anche abbastanza sicuro che ci aiuterà a superare la minaccia Covid.
Questo è il motivo per cui continuo a pensare che l’IT non sia un “costo” ma un modo per ottenere più successo e denaro migliorando l’efficienza di qualsiasi azienda.
Anche Kubernetes ha delle funzionalità specifiche per consentire la mobilità dei dati?
Si, un esempio è Kasten K10 perchè ha tante e avanzate funzionalità di migrazione dei workload (l’argomento sarà ben trattato nei prossimi articoli).
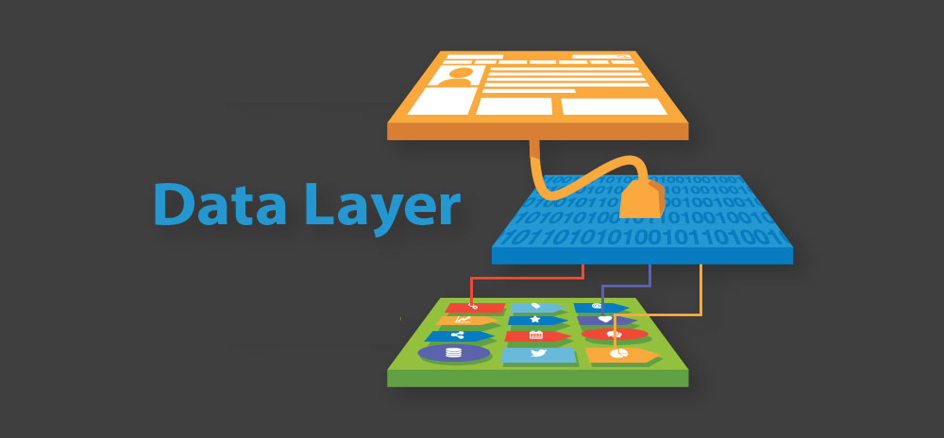
Data-Layer
E i servizi che non possono essere ancora containerizzati?
C’è un modo semplice per spostare i dati tra diverse architetture?
Sì, è possibile utilizzando copie dei dati di VM e Server Fisici.
In questo scenario aziendale, è importante che il software possa creare backup/repliche ovunque si trovino i carichi di lavoro.
È abbastanza? No, il software deve essere in grado di ripristinare i dati all’interno delle architetture.
Ad esempio, un cliente può dover ripristinare alcuni carichi di lavoro on-premise della sua architettura VMware in un cloud pubblico o ripristinare un backup di una VM situata in un cloud pubblico in un ambiente Hyper-V on-premise.
In altre parole, lavorare con Backup/Replica e ripristino in un ambiente multi-cloud.
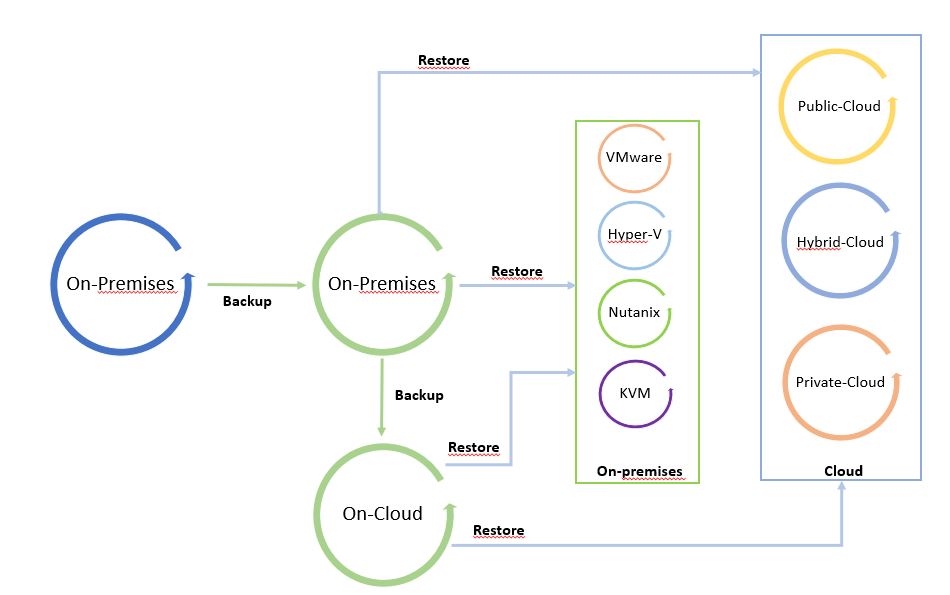
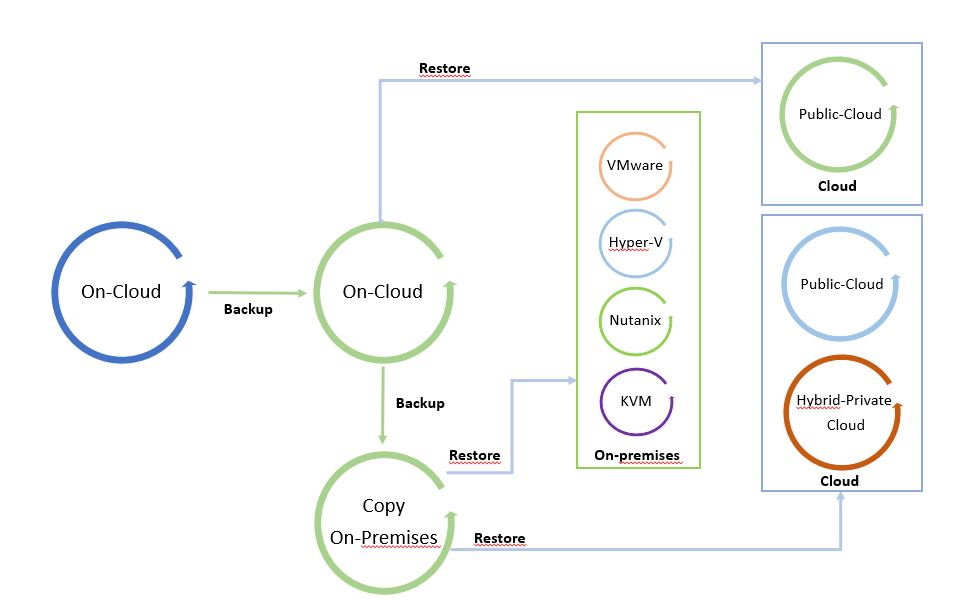
Le immagini successive mostrano il processo dei dati.
L’ho chiamato “Il ciclo dei dati” perché facendo leva su una copia di backup è possibile spostare liberamente i dati da e verso qualsiasi Infrastruttura (Cloud pubblico, ibrido, privato).
Le immagini 1 e 2 sono solo esempi del concetto di mobilità. Possono essere modificati aggiungendo tutte le piattaforme supportate dal software di cloud mobility.
Il punto di partenza dell’immagine 1 è un backup in locale che può essere ripristinato in locale e nel cloud. L’immagine 2 mostra il backup di un carico di lavoro sito in un cloud pubblico ripristinato su cloud o in locale.
È una via circolare in cui i dati possono essere spostati tra le piattaforme.
Nota 4: Un buon suggerimento è quello di utilizzare l’architettura di mobilità dei dati per configurare un sito di ripristino di emergenza a freddo (freddo perché i dati utilizzati per ripristinare il sito sono backup).
Immagine 1
Immagine 2
C’è un ultimo punto per completare questo articolo ed è la funzione Replica.
Nota 5: Per Replica intendo la possibilità di creare un mirror del carico di lavoro di produzione. Rispetto al backup, in questo scenario il carico di lavoro può essere avviato senza alcuna operazione di ripristino perché è già scritto nella “lingua” dell’host-hypervisor.
Lo scopo principale della tecnologia di replica è creare un sito di ripristino di emergenza a caldo (DR).
Maggiori dettagli su come orchestrare il DR sono disponibili su questo sito alla voce Veeam Disaster Recovery Orchestrator (conosciuto anche con il nome di Veeam Availability Orchestrator)
La replica può essere sviluppata con tre diverse tecnologie:
Replica Lun/Archiviazione
Split I/O
Snapshot
Tratterò questi scenari e i casi aziendali di Kasten K10 in articoli futuri.


 mypersonalfile.yaml
mypersonalfile.yaml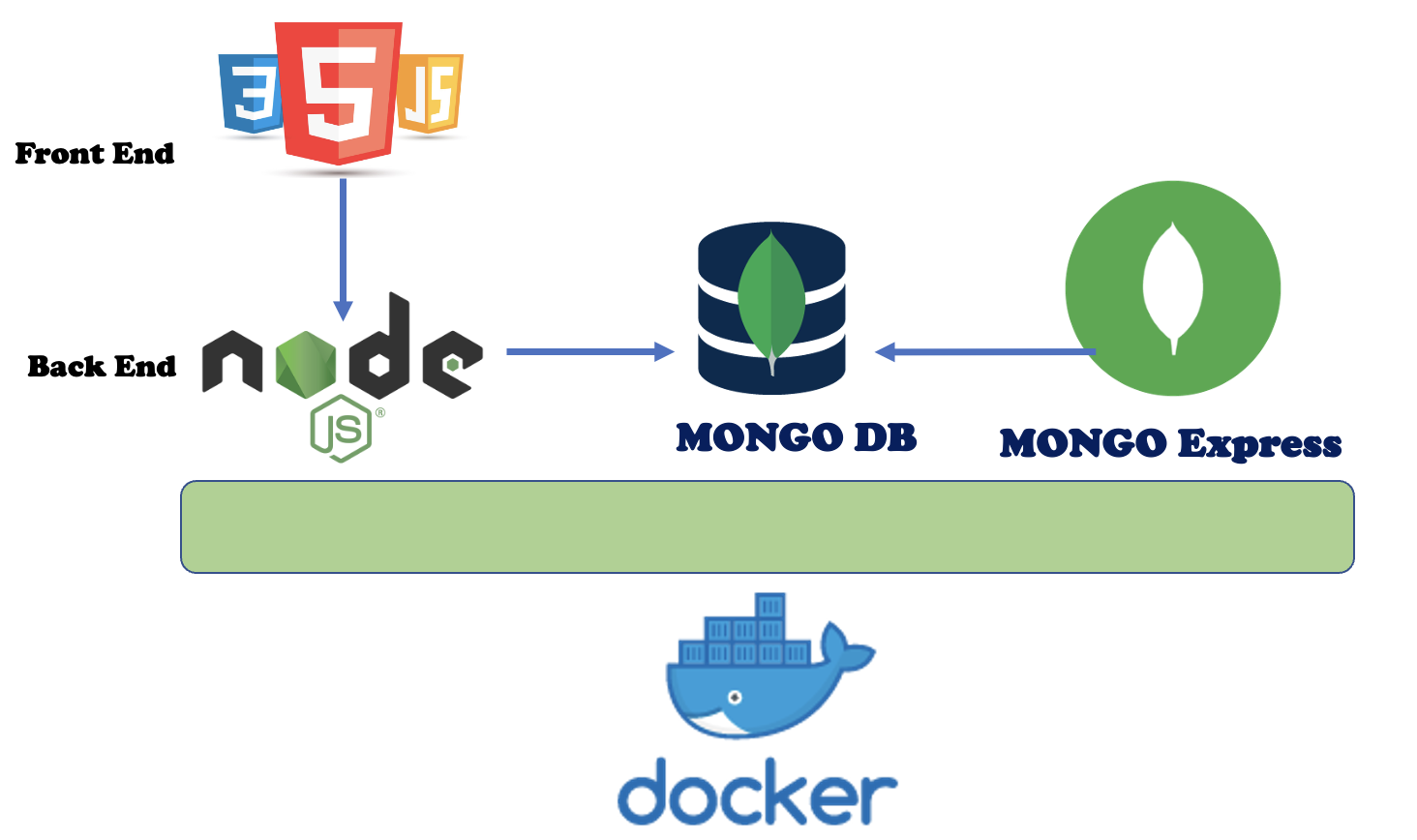 Picture 1
Picture 1




 Picture 1
Picture 1
 Picture 6
Picture 6