

Se negli ultimi 5 anni, la parola Cloud è stata quella più utilizzata (anche in modo inappropriato), negli ultimi cinque mesi la parola che sta rieccheggiando di più nel mondo IT è Digital Transformation.
Da Wikipedia:
“Digital Transformation (DT o DX) è l’adozione della tecnologia digitale per trasformare servizi e aziende, sostituendo processi non digitali o manuali con processi digitali o sostituendo la tecnologia digitale precedente con la tecnologia digitale più recente”.
Ancora: la Digital Transformation deve aiutare le aziende ad essere più competitive attraverso la rapida implementazione di nuovi servizi sempre in linea con le esigenze aziendali.
Nota 1: La trasformazione digitale è il paniere, le tecnologie da utilizzare sono le mele, i servizi sono i mezzi di trasporto, i negozi sono i clienti/clienti.
1. Tutte le architetture IT esistenti possono funzionare per la Trasformazione Digitale?
Preferisco rispondere ricostruendo la domanda con parole più appropriate:
2. La trasformazione digitale richiede che dati, applicazioni e servizi si spostino da e verso architetture diverse?
Sì, questo è un must ed è stato nominato Data Mobility.
3. La Data-Mobility significa che i servizi possono essere indipendenti dall’infrastruttura sottostante?
La miglior risposta credo che sia: nonostante al giorno d’oggi non esista un linguaggio standard che permetta a diverse architetture/infrastruttura di dialogare tra loro (on-premises & on cloud), le tecnologie di Data-mobility sono in grado di superare tale limitazione.
4. La Data Mobility è indipendente dai fornitori?
Quando uno standard viene rilasciato, tutti i fornitori vogliono implementarlo al più presto perché sono sicuri che queste funzionalità miglioreranno le loro entrate. Attualmente, questo standard non esiste ancora.
Nota 3: penso che il motivo sia che ci sono così tanti oggetti da contare, analizzare e sviluppare che lo sforzo economico per farlo non è al momento giustificato
5. Esiste già una tecnologia Ready “Data-Mobility”?
La risposta potrebbe essere piuttosto lunga ma, per farla breve, ho scritto il seguente articolo che si compone di due parti principali:
Livello applicazione (contenitore – Kubernetes)
Livello dati (backup, replica)
Application Layer – Container – Kubernetes
Nel mondo IT, i servizi sono eseguiti in ambienti virtuali (VMware, Hyper-V, KVM, ecc.).
Vi sono ancora alcuni servizi che girano su architetture legacy (Mainframe, AS400 ….), (vecchi non significa che non siano aggiornati ma solo che hanno una storia molto lunga)
Nei prossimi anni i servizi verranno implementati in un’apposita “area” denominata “container”.
Il contenitore viene eseguito nel sistema operativo e può essere ospitato in un’architettura Virtuale/Fisica/Cloud.
Perché i contenitori e le competenze su di essi sono così richiesti?
a. L’esigenza degli IT Manager è quella di spostare i dati tra le architetture al fine di migliorare la resilienza e ridurre i costi.
b. La tecnologia Container semplifica la scrittura del codice dello sviluppatore perché ha un linguaggio standard e ampiamente utilizzato.
c. I servizi eseguiti sul container sono veloci da sviluppare, aggiornare e modificare.
d. Il contenitore è “de facto” un nuovo standard che ha un grande vantaggio. Superare l’ostacolo della mancanza di standard di comunicazione tra le architetture (private, ibride e cloud pubblico).
Un approfondimento sul punto d.
Ogni azienda ha il proprio core business e tutte hanno bisogno della tecnologia informatica.
Qualsiasi dimensione dell’azienda?
Sì, basti pensare all’ uso del cellulare, per prenotare un tavolo al ristorante o acquistare un biglietto per un film. Sono anche abbastanza sicuro che ci aiuterà a superare la minaccia Covid.
Questo è il motivo per cui continuo a pensare che l’IT non sia un “costo” ma un modo per ottenere più successo e denaro migliorando l’efficienza di qualsiasi azienda.
Anche Kubernetes ha delle funzionalità specifiche per consentire la mobilità dei dati?
Si, un esempio è Kasten K10 perchè ha tante e avanzate funzionalità di migrazione dei workload (l’argomento sarà ben trattato nei prossimi articoli).
Data-Layer
E i servizi che non possono essere ancora containerizzati?
C’è un modo semplice per spostare i dati tra diverse architetture?
Sì, è possibile utilizzando copie dei dati di VM e Server Fisici.
In questo scenario aziendale, è importante che il software possa creare backup/repliche ovunque si trovino i carichi di lavoro.
È abbastanza? No, il software deve essere in grado di ripristinare i dati all’interno delle architetture.
Ad esempio, un cliente può dover ripristinare alcuni carichi di lavoro on-premise della sua architettura VMware in un cloud pubblico o ripristinare un backup di una VM situata in un cloud pubblico in un ambiente Hyper-V on-premise.
In altre parole, lavorare con Backup/Replica e ripristino in un ambiente multi-cloud.
Le immagini successive mostrano il processo dei dati.
L’ho chiamato “Il ciclo dei dati” perché facendo leva su una copia di backup è possibile spostare liberamente i dati da e verso qualsiasi Infrastruttura (Cloud pubblico, ibrido, privato).
Le immagini 1 e 2 sono solo esempi del concetto di mobilità. Possono essere modificati aggiungendo tutte le piattaforme supportate dal software di cloud mobility.
Il punto di partenza dell’immagine 1 è un backup in locale che può essere ripristinato in locale e nel cloud. L’immagine 2 mostra il backup di un carico di lavoro sito in un cloud pubblico ripristinato su cloud o in locale.
È una via circolare in cui i dati possono essere spostati tra le piattaforme.
Nota 4: Un buon suggerimento è quello di utilizzare l’architettura di mobilità dei dati per configurare un sito di ripristino di emergenza a freddo (freddo perché i dati utilizzati per ripristinare il sito sono backup).
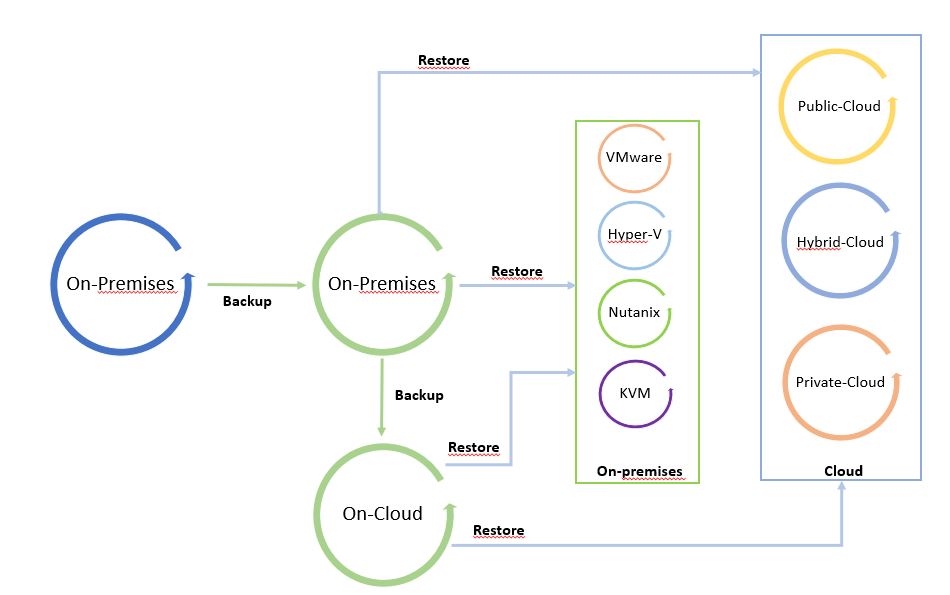
Immagine 1
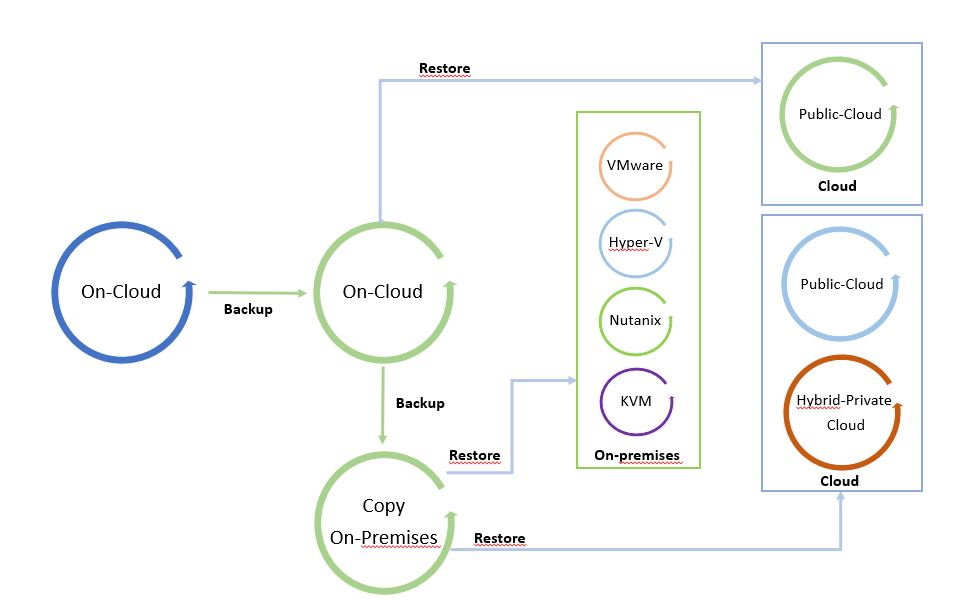
Immagine 2
C’è un ultimo punto per completare questo articolo ed è la funzione Replica.
Nota 5: Per Replica intendo la possibilità di creare un mirror del carico di lavoro di produzione. Rispetto al backup, in questo scenario il carico di lavoro può essere avviato senza alcuna operazione di ripristino perché è già scritto nella “lingua” dell’host-hypervisor.
Lo scopo principale della tecnologia di replica è creare un sito di ripristino di emergenza a caldo (DR).
Maggiori dettagli su come orchestrare il DR sono disponibili su questo sito alla voce Veeam Disaster Recovery Orchestrator (conosciuto anche con il nome di Veeam Availability Orchestrator)
La replica può essere sviluppata con tre diverse tecnologie:
- Replica Lun/Archiviazione
- Split I/O
- Snapshot
Tratterò questi scenari e i casi aziendali di Kasten K10 in articoli futuri.
A presto