
 Persistent Data
Persistent Data
Nei precedenti articoli, abbiamo visto che se un POD viene dismesso o il container viene riavviato, tutti i dati presenti sul file system del POD vengono cancellati.
E’ un approccio vincente per tutte quelle applicazioni stateless (ad esempio un front-end web) ma non lo è per le applicazioni stateful dove ad esempio non registrare anche un record di un DataBase significa perdere informazioni vitali per il servizio erogato.
Kubernetes supera brillantemente l’ ostacolo attraverso l’utilizzo della tecnologia Persistent Data.
E’ il file yaml che definisce nel POD i Persisten Data attraverso le voci:
- Volumes che descrive i volumi disponibili per il POD.
- VolumeMounts che descrive il percorso per l’utilizzo del volume (ad esempio /mydata/)
I Volumi sono categorizzati in tre principali categorie create in base al loro utilizzo:
1- Comunicazione/sincronizzazione
E’ il volume condiviso per realizzare la sincronizzazzione con le immagini di una Git remota.
La vita del volume è limitata all’esistenza del POD ed il volume può essere condiviso tra più container.
2- Dati Persistenti
Per garantire l’alta affidabilità e le migliori performance, i POD devono potersi spostarsi liberamente tra i nodi del cluster kubernetes.
Di conseguenza i volumi che contengono informazioni persistenti e vitali dell’applicazione devono essere sempre raggiungibili dal POD.
Kubernetes per garantire la visibilità supporta molte tipologie di volumi ad esempio NFS, iSCSI, Elastic Block Store di Amazon, File e Disk Storage Azure, nonché Google Persistent Disk.
Nota1: In caso di spostamento del POD, Kubernetes in automatico è in grado di smontare il volume dal vecchio host e renderlo disponibile sul nuovo.
3- Filesystem host
Alcune applicazioni non hanno bisogno solo di un volume persistente, ma anche di un filesystem disponibile a livello di host. La necessità è indirizzata attraverso il volume hostPath (Ad esempio /var/mygp/).
Resource Management
Il costo di funzionamento di una macchina in un datacenter, è indipendente dalla quantità di CPU & RAM che utilizza la singola VM in esercizio.
Garantire invece che all’interno dell’infrastruttura, le risorse CPU & RAM siano distribuite al meglio, impatta l’efficenza dell’ambiente.
Esempio:
Immaginiamo due servizi. Il primo utilizza il 20% della memoria di una VM configurata con 5GB di RAM, il secondo utilizza il 50% di una seconda VM configurata con 4GB RAM.
L’utilizzo totale di memoria RAM è di 1+2=3GB delle 9GB totale assegnate.
La metrica di utilizzo (MU) è definita come il valore percentuale tra il rapporto della quantità di risorse attivamente utilizzate e la quantità di risorse acquistate.
Nel nostro esempio MU=3/9= 33%
Al fine di controllare l’uso delle risorse, Kubernetes consente agli utenti di specificare due diverse metriche a livello di POD.
- Resource Request specifica la quantità minima assegnabile alla risorsa.
- Resource limits specifica la quantità massima assegnabile all’applicazione.
L’esempio di figura 1 mostra l’iun esempio di limite di risorse
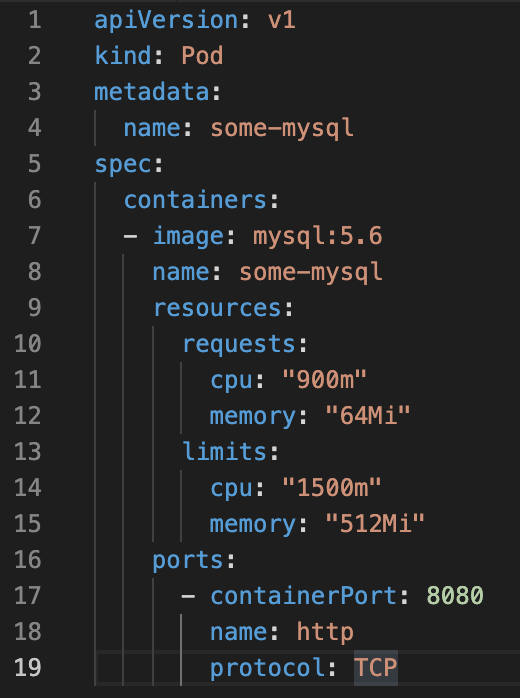 Figura 1
Figura 1