This article explains how to configure the Veeam Disaster Recovery Orchestrator (VDrO) administration menu.
Before proceeding to the administration phase, it is essential to have already labeled the resources that will have to be part of the Disaster Recovery plans.
The classification was illustrated in the previous article, available by clicking on the following link: VDrO – VOne – Tagging .
Note 1 : To access the administration menu, select the item called “Administration” (see image 1)
Picture 1
The configuration of the administration menu is divided into three main areas:
In the first, the following are set:
The name of the VDrO Server and the contact name (image 2).
connections to Veeam Backup & Replication Servers (VBR) (image 3)
connections to vCenters (image 4)
the optional connection to the storage (image 5) (refer to this article to find out the details)
picture 2
Picture 3
Picture 4
Picture 5
The second area identifies the resources to be added to the DR plans through tagging:
The recovery location (image 6)
In the recovery location the datastores where the VM filesystems will reside (image 7)
Network mapping (image 8)
IP address remapping (image 9)
Note 2: The operations described above are possible if and only if all necessary resources have been tagged.
Note 3: Automatic remapping of IP addresses when starting a DR plan is only available for Windows VMs.
Picture 6
Picture 7
Image 8
Image 9
In the third area are identified:
User profiling. In simple terms, the VDrO allows you to create users capable of administering only specific workloads which are called “scopes” (image 10).
The assignment of the DataLabs to the “scopes”. Remember that the DataLabs allow you to verify that the DR plan is usable (image 11).
Image 10
Image 11
The last configuration allows you to link the group of VMs replicated or saved via backup (called VM Groups) to the users’ scopes.
For example, image 12 shows that the VM Group “B&R Job – Replication VAO Win 10” is assigned (included) to both the Admin and Linux scopes.
Image 10
In the next and last article, we will find out how to create and verify a DR plan.
In my lab, the Disaster Recovery site consists of a single ESX 7.01 host.
It is managed by a virtual vCenter (called vCenter-DR ), which relates exclusively to the hardware resources made available by the ESX 7.01 host itself.
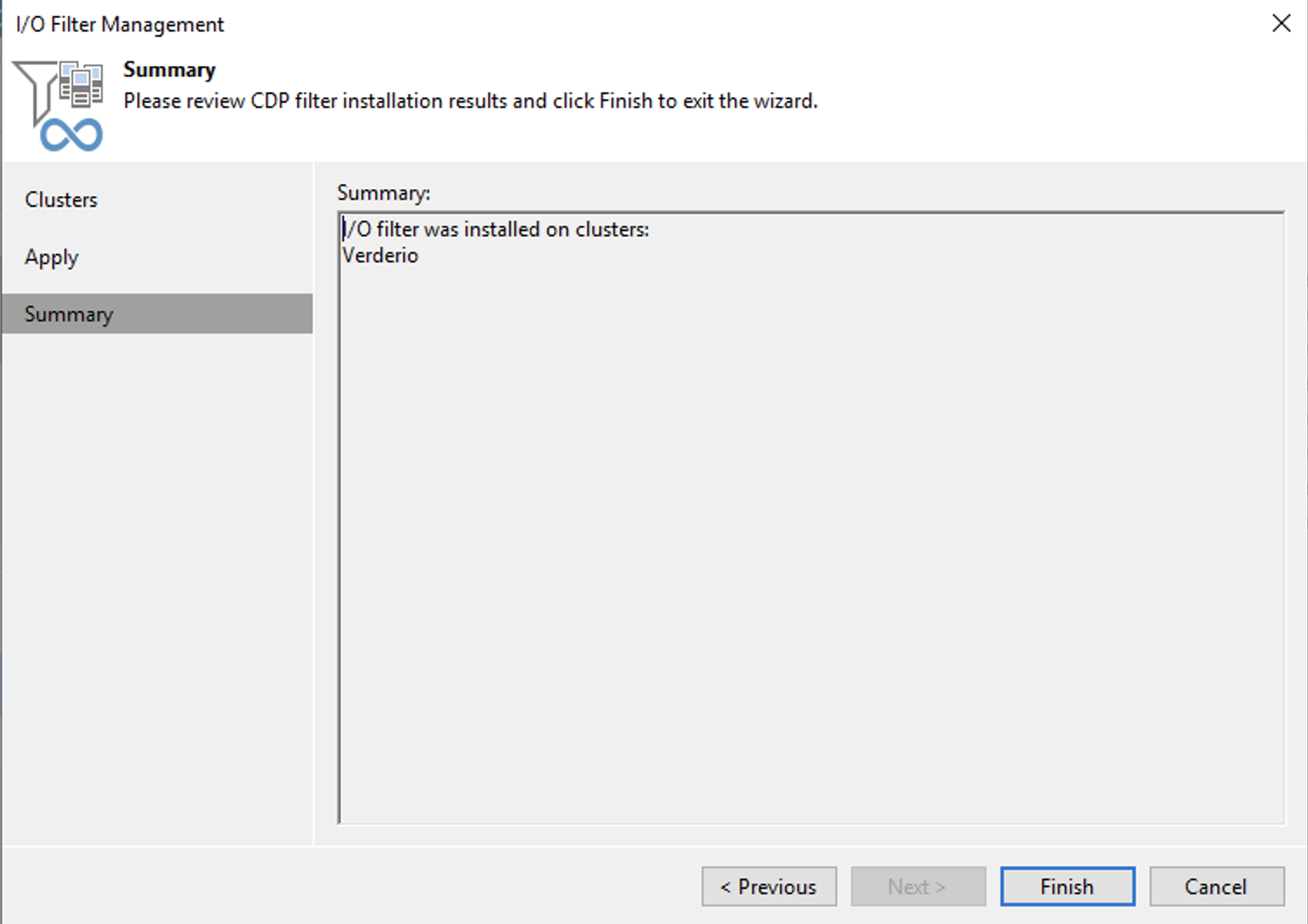
Last month Veeam Software released the Veeam Backup & Replication 11A update.
Among the various improvements introduced, my attention was focused on the new drivers (called I / O filters ) of the CDP component.
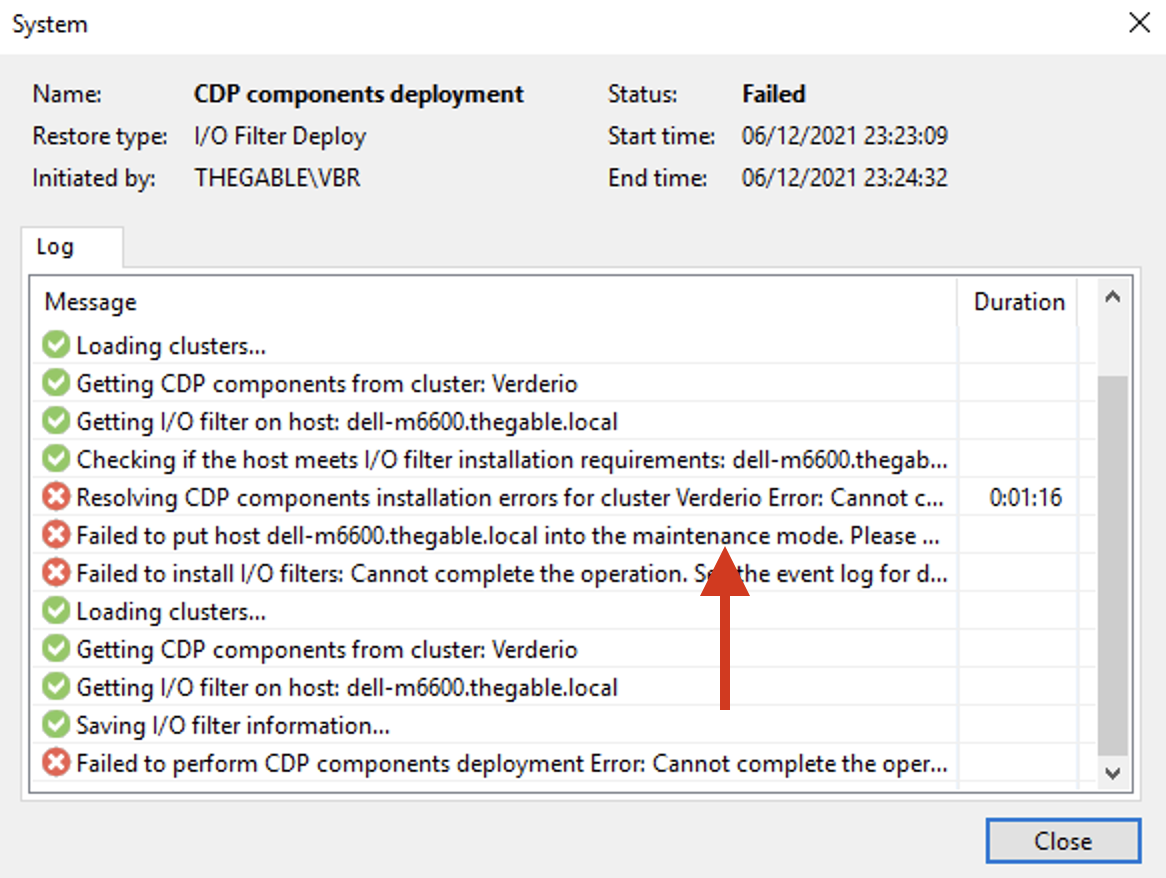
If in the main cluster, the upgrade was simple, immediate, and painless (given the presence of more hosts under an additional vCenter), a complication related to the hardware architecture was generated for the Disaster Recovery site.
The update failed, as it was impossible to put the ESX 7.01 host in maintenance mode without actually turning off the vCenter-DR that managed it (see image 1).
Picture 1
How was it possible to overcome this obstacle without changing the cluster configuration? (I.e. without adding an additional ESX 7.01 Host)
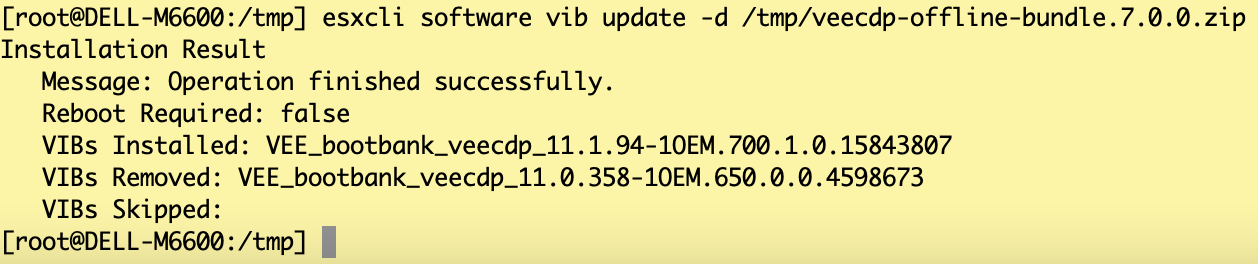
Copy the Veeam CDP package to the ESX 7.01 host (veecdp-offline-bundle.7.0.0.zip)
Installation of the package through the command “esxcli software vib update -d /yourpath/veecdp-offline-bundle.7.0.0.zip” (see Image 2)
Image 2
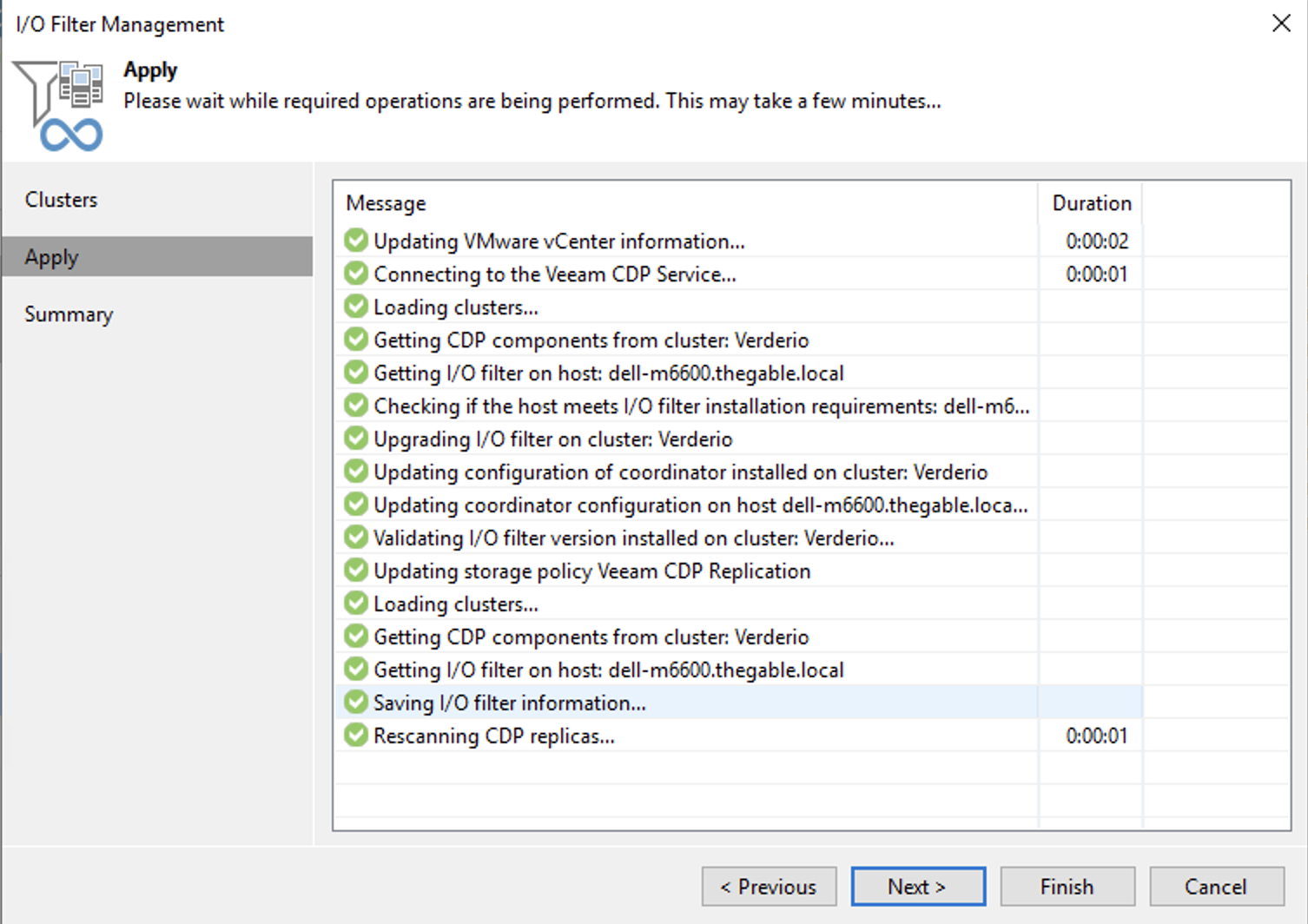
At the end of this first phase, it was now sufficient to repeat the standard update procedure (see images 3,4, and 5).
Picture 3
Picture 4
Picture 5
The check that guarantees that the procedure followed is correct is to create a CDP Replication Job, wait for it to finish without errors and for the failover procedure to be started.
If Cloud has been the most used word in the last five years, the words that have been buzzing the IT world in the last five months are Digital Transformation
From Wikipedia:
“Digital Transformation (DT or DX) is the adoption of digital technology to transform services and businesses, through replacingnon-digital or manual processes with digital processes or replacing older digital technology with newer digital technology”.
Or: Digital Transformation must help companies to be more competitive through the fast deployment of new services always aligned with business needs.
Note 1: Digital transformation is the basket, technologies to be used are the apples, services are the means of transport, shops are clients/customers.
1. Can all the already existing architectures work for Digital Transformation?
I prefer to answer rebuilding the question with more appropriate words:
2. Does Digital transformation require that data, applications, and services move from and to different architectures?
Yes, this is a must and It is called Data Mobility
Note 2: Data mobility regards the innovative technologies able to move data and services among different architectures, wherever they are located.
3. Does Data-Mobility mean that the services can be independent of the below Infrastructure?
Actually, it is not completely true; it means that, despite nowadays there is not a standard language allowing different architecture/infrastructure to talk to each other, the Data-mobility is able to get over this limitation.
4. Is it independent from any vendors?
When a standard is released all vendors want to implement it asap because they are sure that these features will improve their revenue. Currently, this standard doesn’t still exist.
Note 3: I think the reason is that there are so many objects to count, analyze, and develop that the economical effort to do it is at the moment not justified
5. Is already there a Ready technology “Data-Mobility”?
The answer could be quite long but, to do short a long story, I wrote the following article that is composed of two main parts:
Application Layer (Container – Kubernetes)
Data Layer (Backup, Replica)
Application Layer – Container – Kubernetes
In the modern world, services are running in a virtual environment (VMware, Hyper-V, KVM, etc).
There are still old services that run on legacy architecture (Mainframe, AS400 ….), (old doesn’t mean that they are not updated but just they have a very long story)
In the next years, the services will be run in a special “area” called “container“.
The container runs on Operating System and can be hosted in a virtual/physical/Cloud architecture.
Why containers and skills on them are so required?
There are many reasons and I’m listing them in the next rows.
The need of IT Managers is to move data among architectures in order to improve resilience and lower costs.
The Container technology simplifies the developer code writing because it has a standard widely usedlanguage.
The services ran on the container are fast to develop, update and change.
The container is de facto a new standard that has a great advantage. It gets over the obstacle of missing standards among architectures (private, hybrid, and public Cloud).
A deep dive about point d.
Any company has its own core business and in the majority of cases, it needs IT technology.
Any size of the company?
Yes, just think about your personal use of the mobile phone, maybe to book a table at the restaurant or buying a ticket for a movie. I’m also quite sure it will help us get over the Covid threat.
This is the reason why I’m still thinking that IT is not a “cost” but a way to get more business and money improving efficiency in any company.
Are there specif features to allow data mobility in the Kubernetes environment?
Yes, an example is Kasten K10 because it has many and advanced workload migration features (the topic will be well covered in the next articles).
Data-Layer
What about services that can’t be containerized yet?
Is there a simple way to move data among different architectures?
Yes, that’s possible using copies of the data of VMs, Physical Servers.
In this business scenario, it’s important that the software can create Backup/Replicas wherever the workloads are located.
Is it enough? No, the software must be able to restore data within architectures.
For example, a customer can need to restore some on-premises workloads of his VMware architecture in a public cloud, or restore a backup of a VM located in a public cloud to a Hyper-V on-premises environment.
In other words, working with Backup/Replica and restore in a multi-cloud environment.
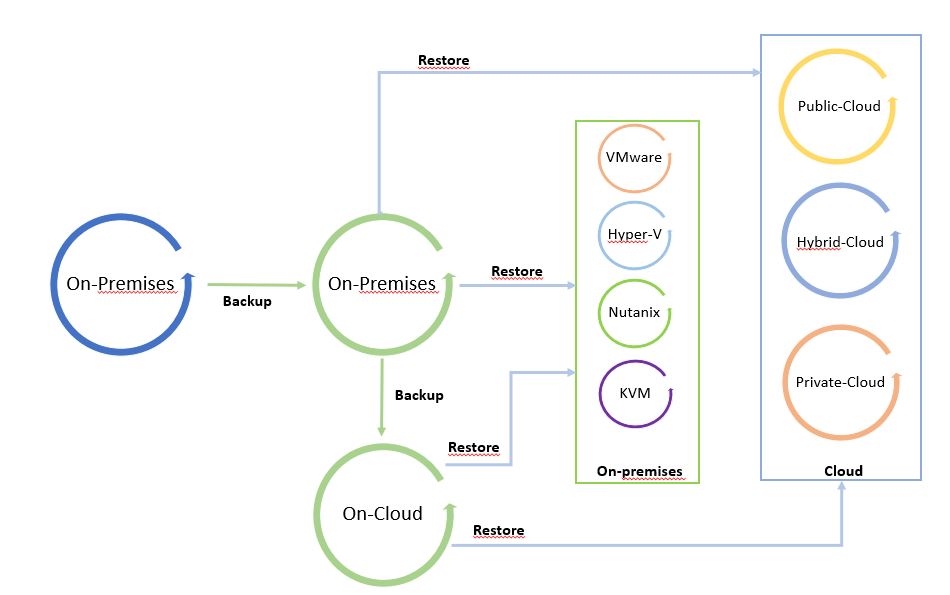
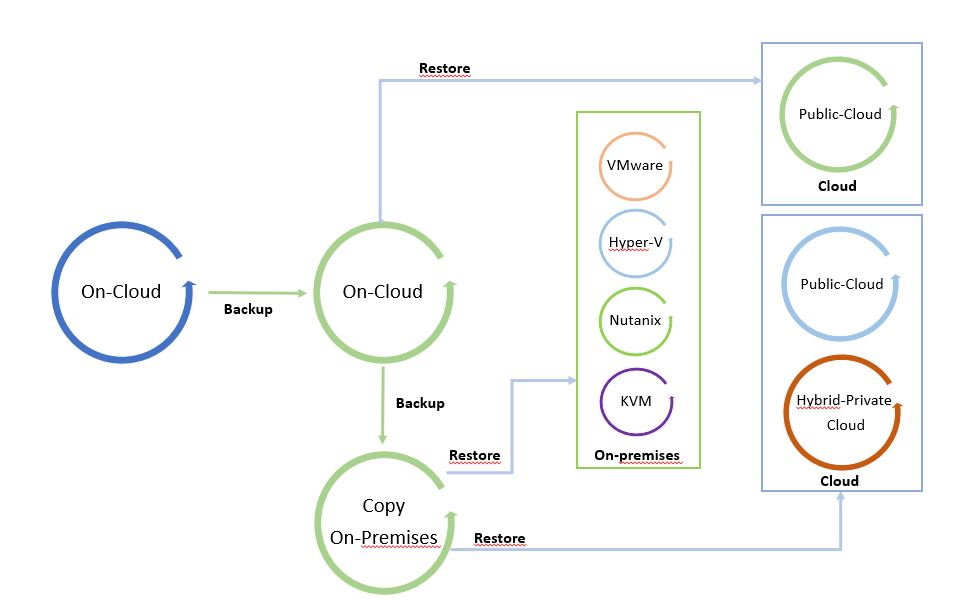
The next pictures show the Data Process.
I called it “The cycle of Data” because leveraging from a copy it is possible to freely move data from and to any Infrastructure (Public, hybrid, private Cloud).
Pictures 1 and 2 are just examples of the data-mobility concept. They can be modified by adding more platforms.
The starting point of Picture 1 is a backup on-premises that can be restored on-premises and on-cloud. Picture 2 shows backup of a public cloud workload restored on cloud or on-premises.
It’s a circle where data can be moved around the platforms.
Note 4: A good suggestion is to use data-mobility architecture to set up a cold disaster recovery site (cold because data used to restore site are backup).
Picture 1
Picture 2
There is one last point to complete this article and that is the Replication features.
Note 5: For Replica I intend the way to create a mirror of the production workload. Comparing to backup, in this scenario the workload can be switched on without any restore operation because it is already written in the language of the host hypervisor.
The main scope of replica technology is to create a hot Disaster Recovery site.
More details about how to orchestrate DR are available on this site at the voice Veeam Availability Orchestrator (Now Veeam Disaster Recovery Orchestrator)
The replica can be developed with three different technologies:
Lun/Storage replication
I/O split
Snapshot based
I’m going to cover those scenarios and Kasten k10 business cases in future articles.

 Picture 1
Picture 1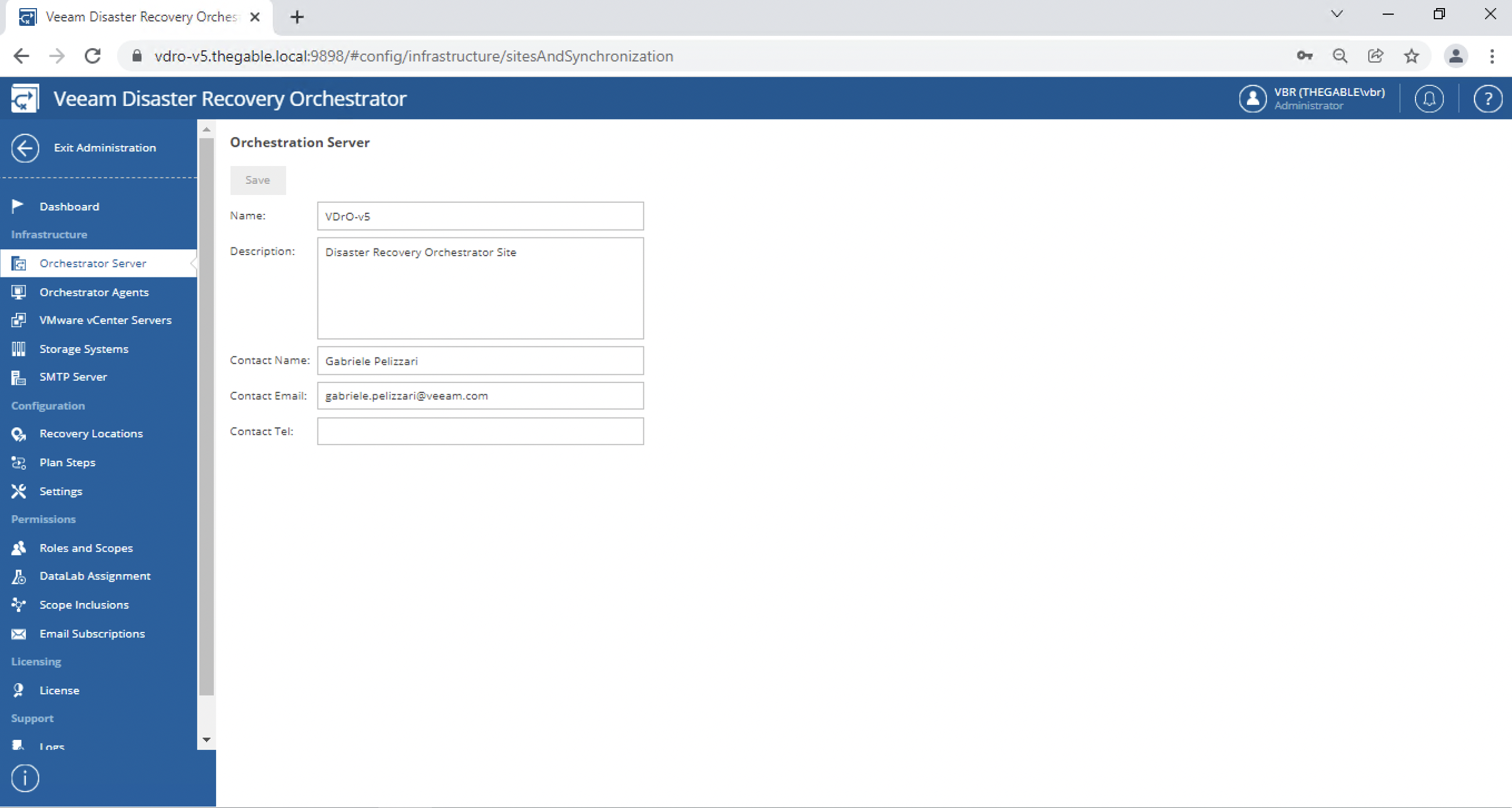 picture 2
picture 2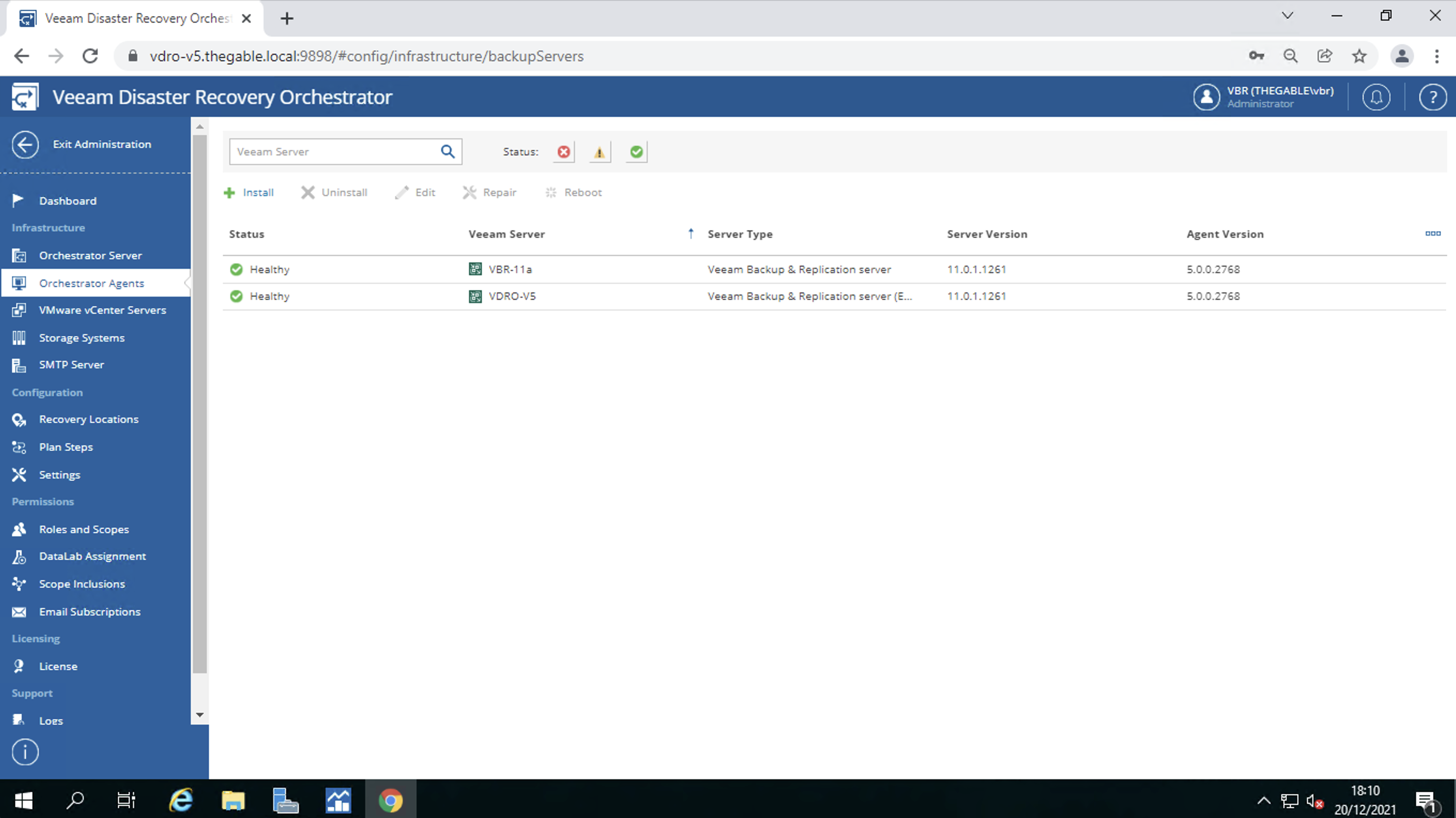 Picture 3
Picture 3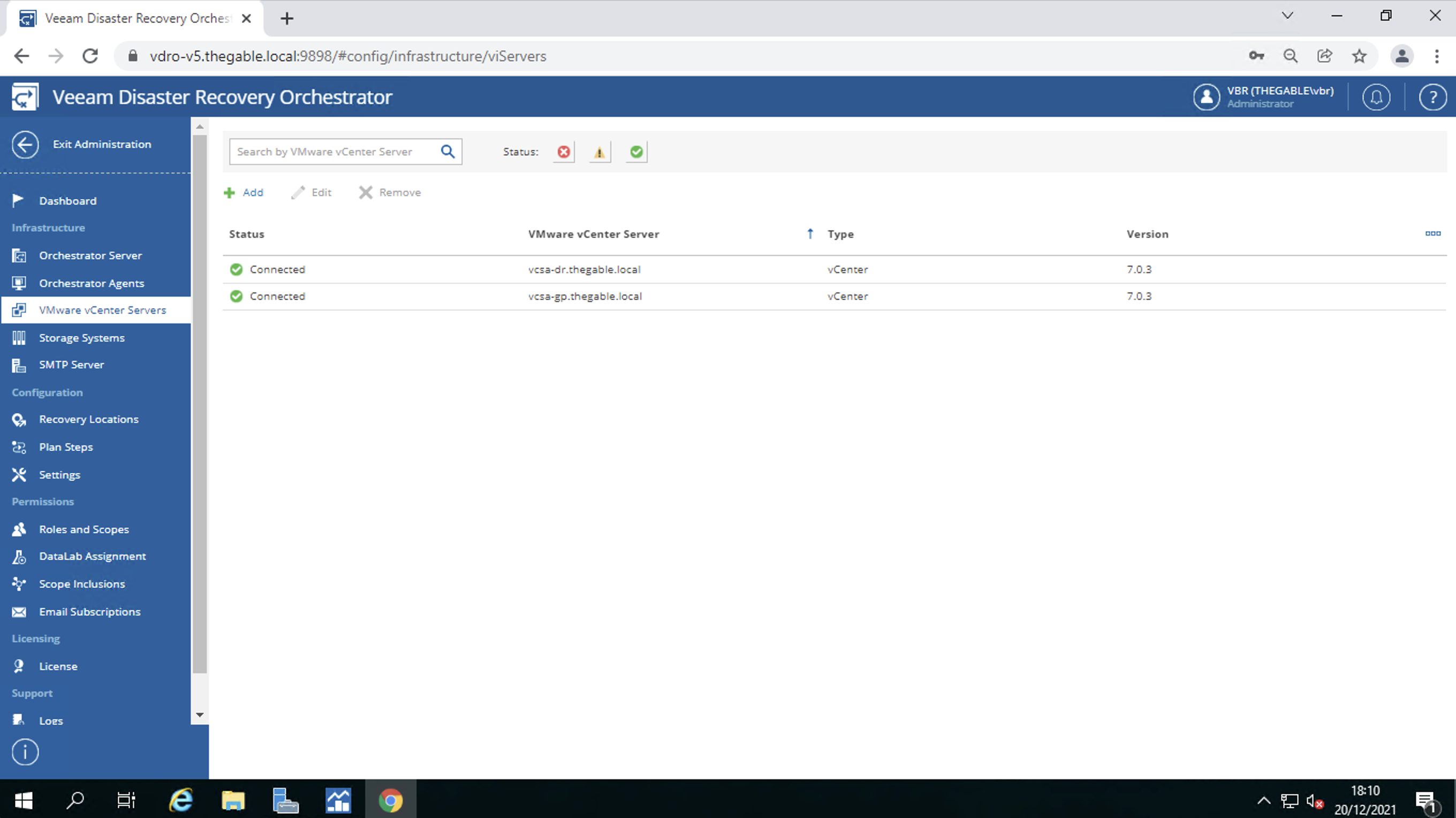 Picture 4
Picture 4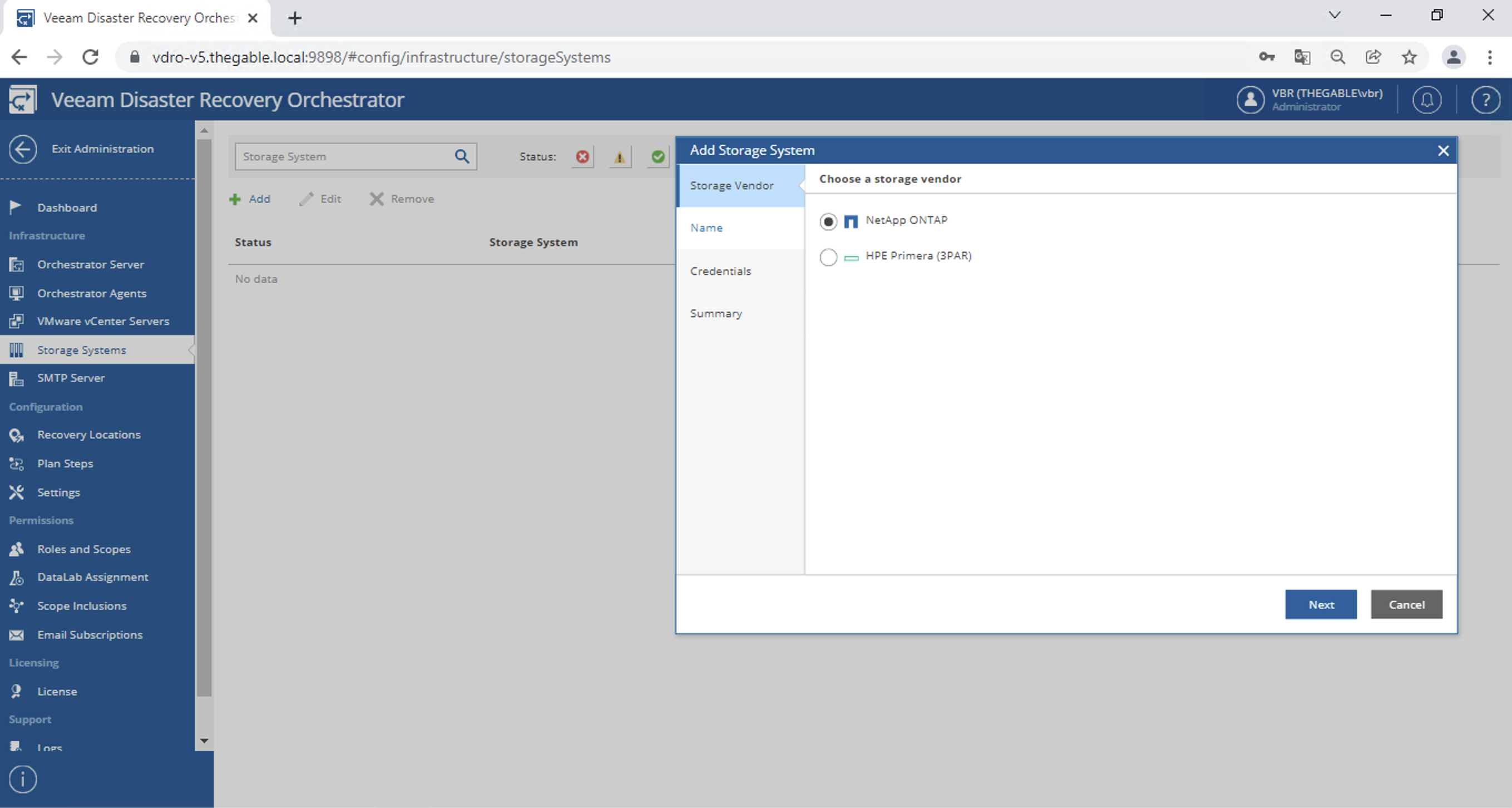 Picture 5
Picture 5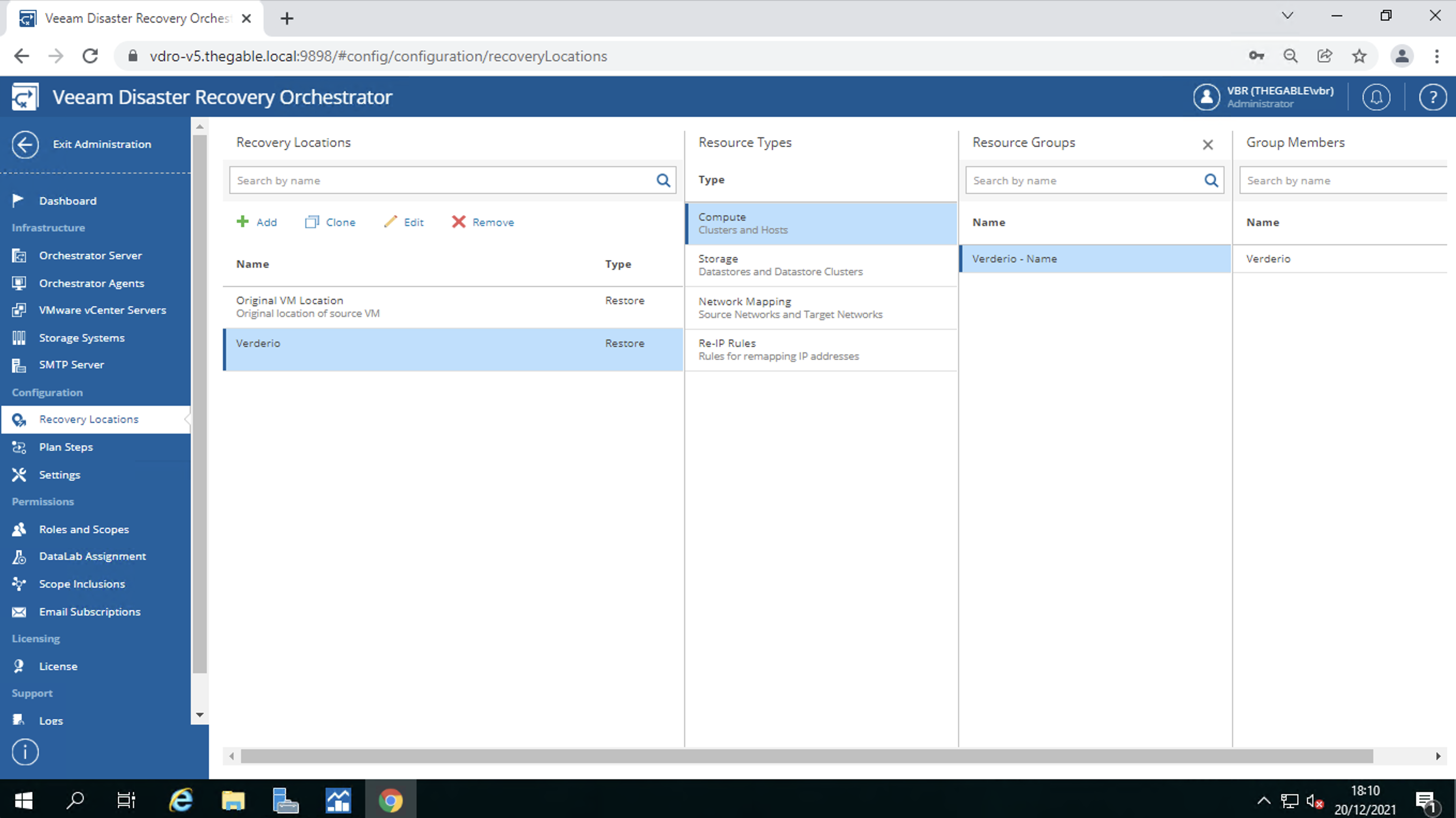 Picture 6
Picture 6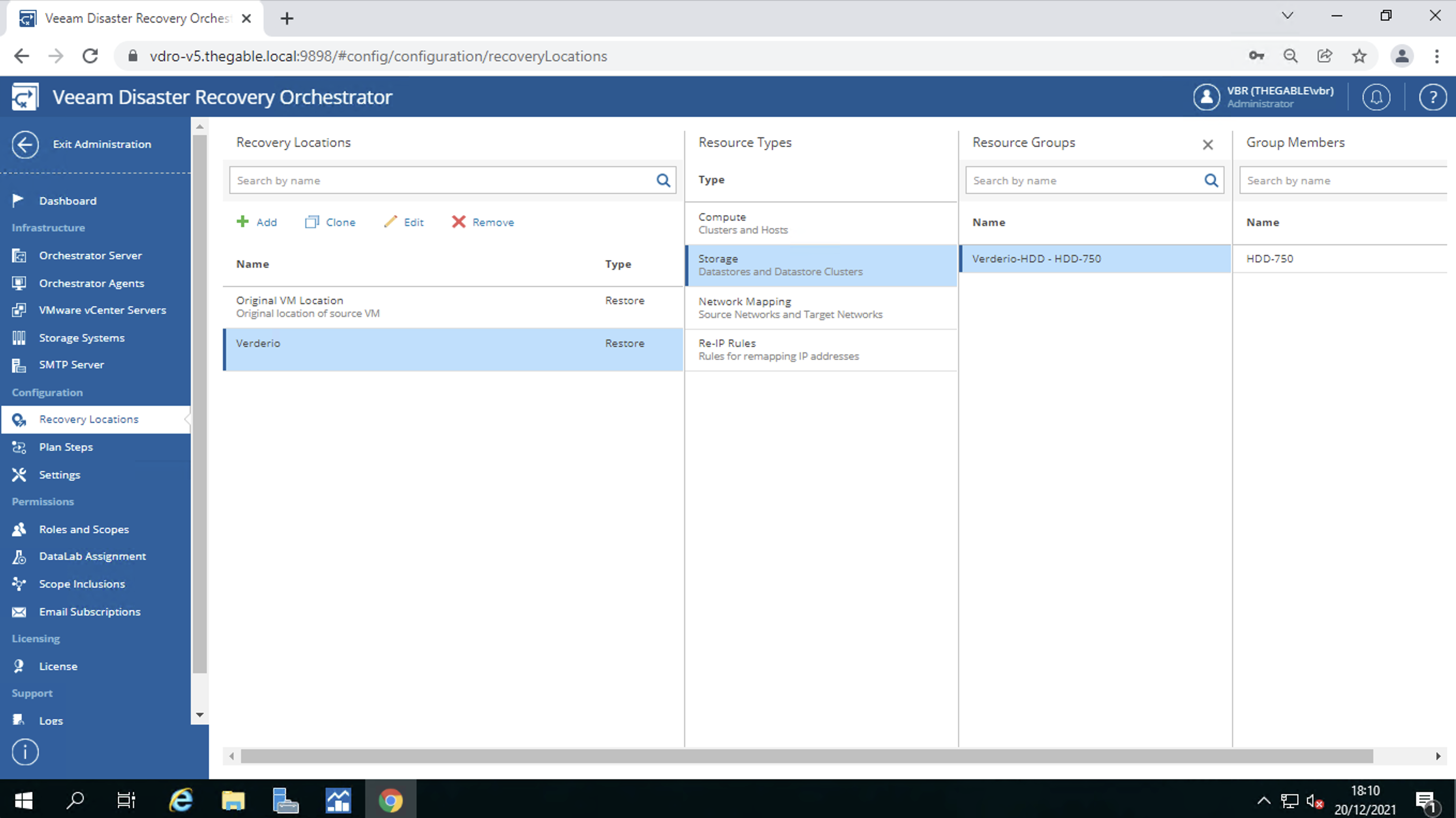 Picture 7
Picture 7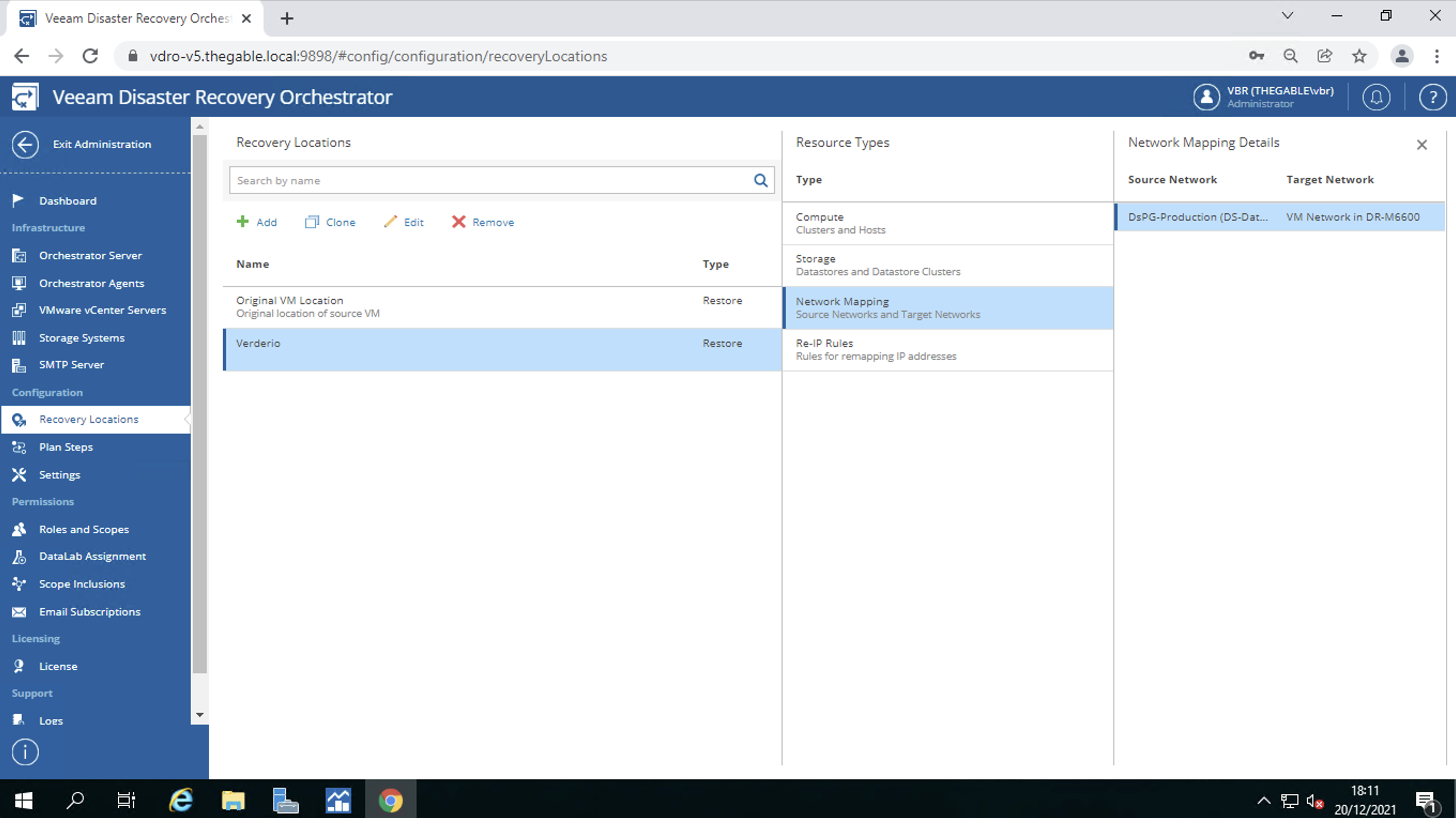 Image 8
Image 8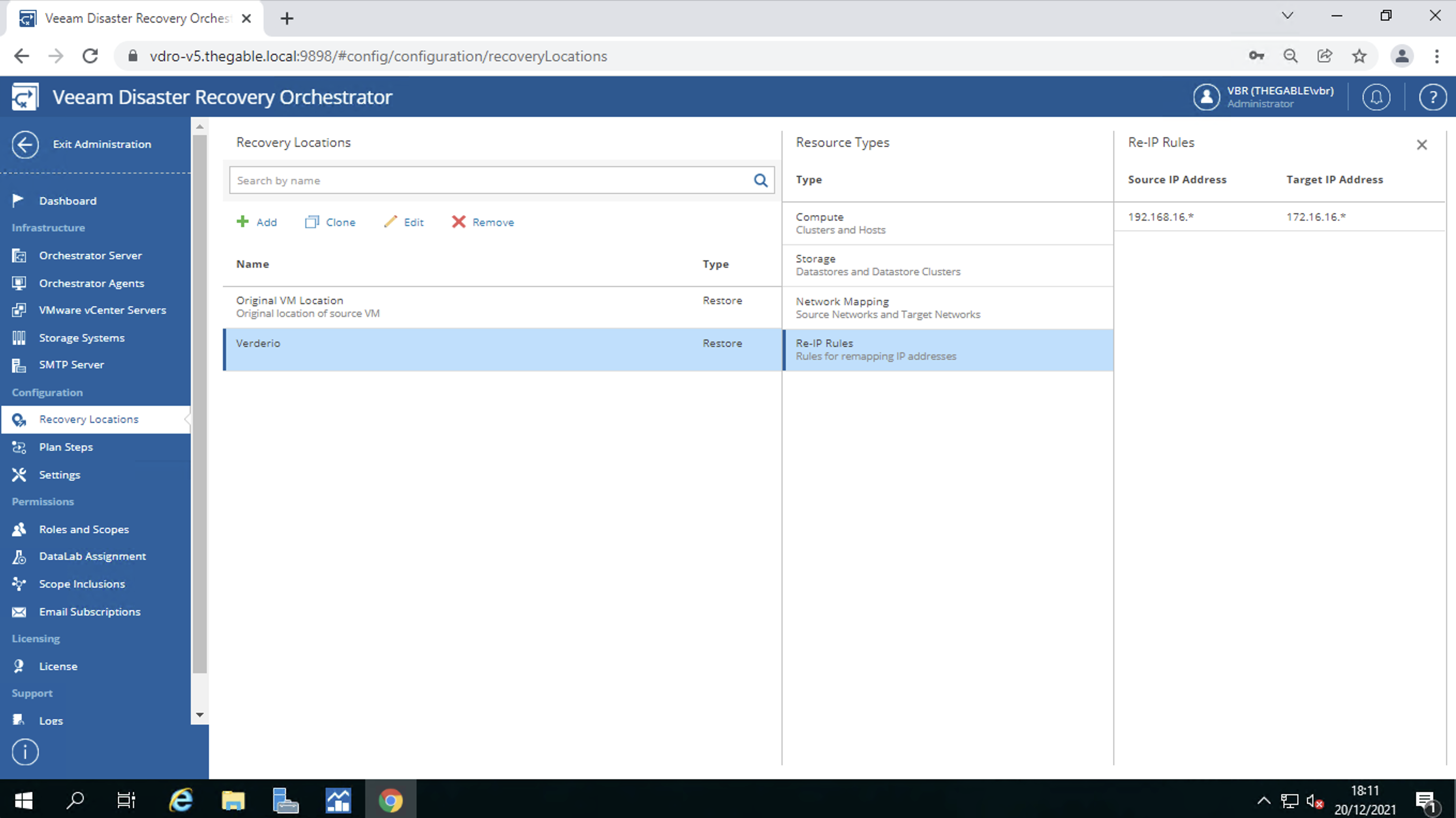 Image 9
Image 9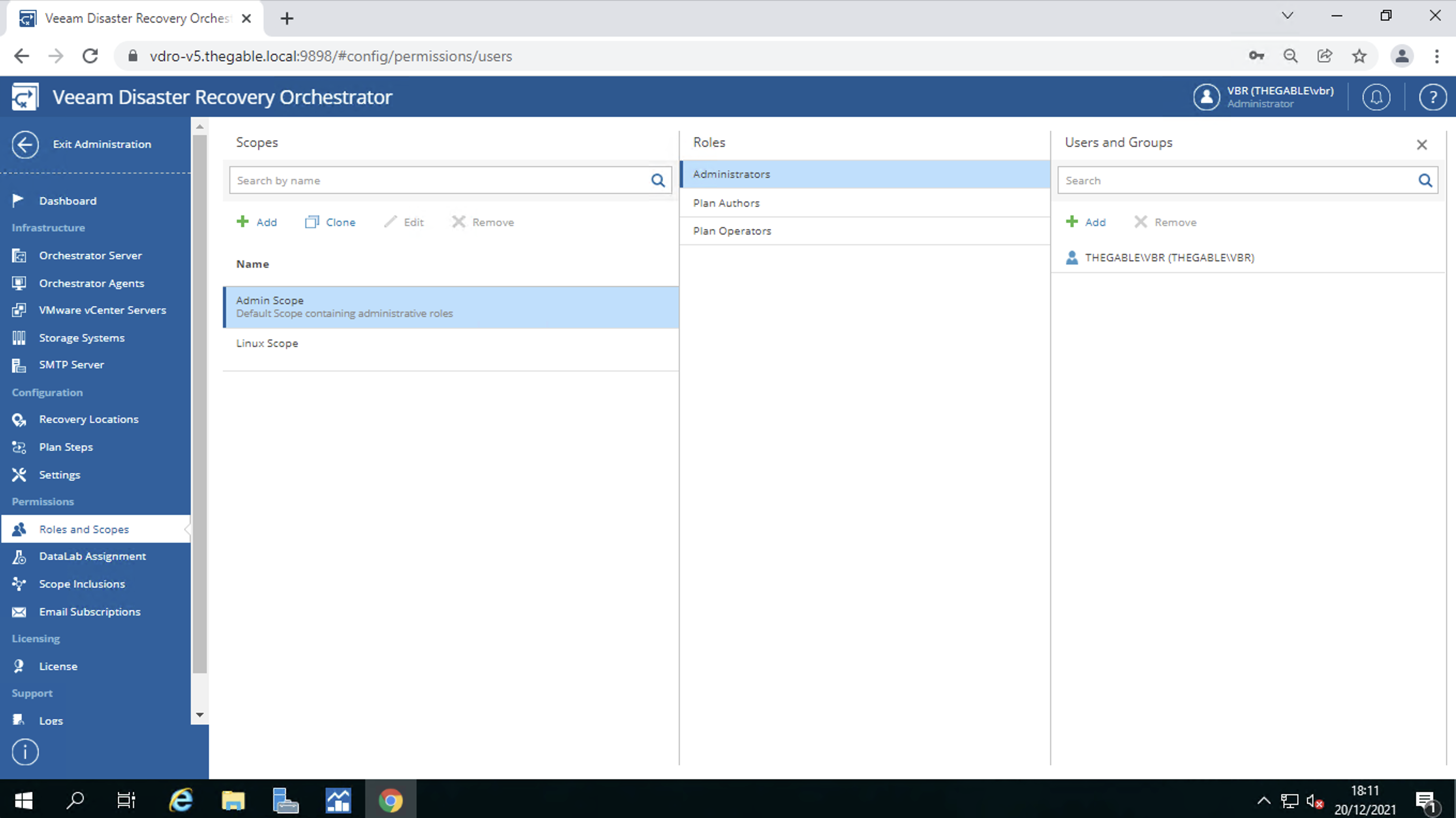 Image 10
Image 10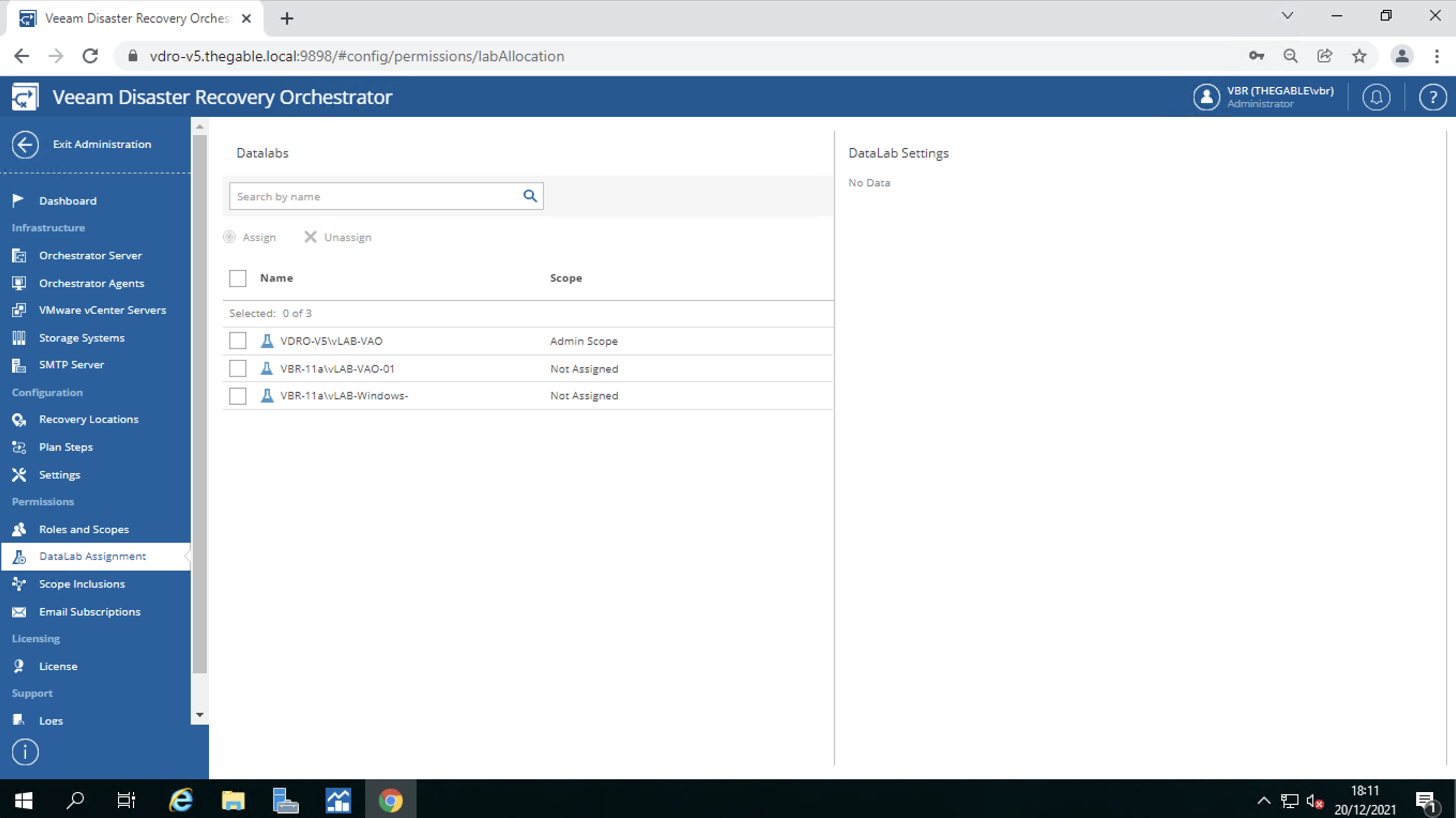 Image 11
Image 11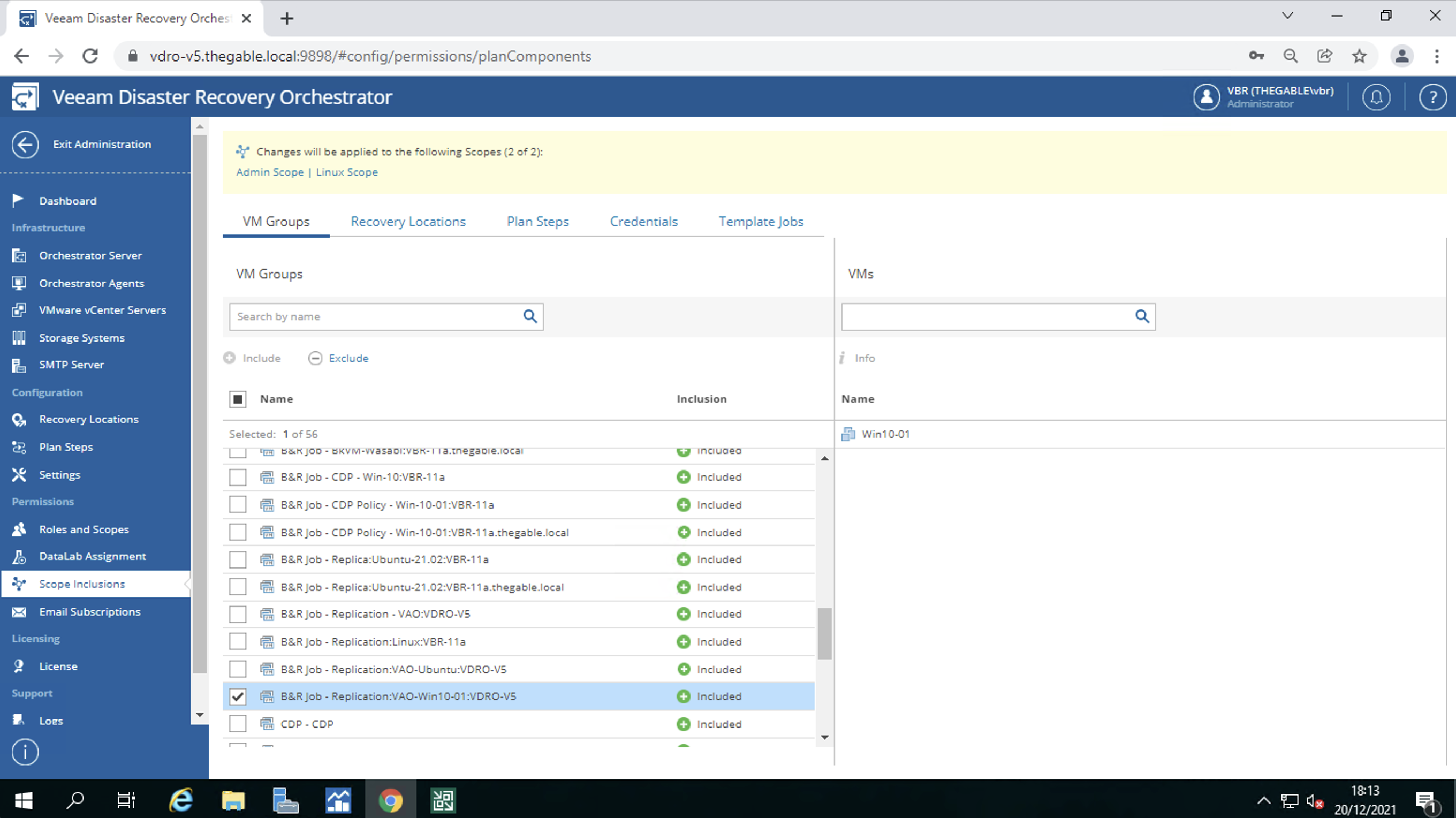 Image 10
Image 10